
【NLP】【CS224N】textcnn
TextCNN
Convolutional Neural Networks for Sentence Classification:
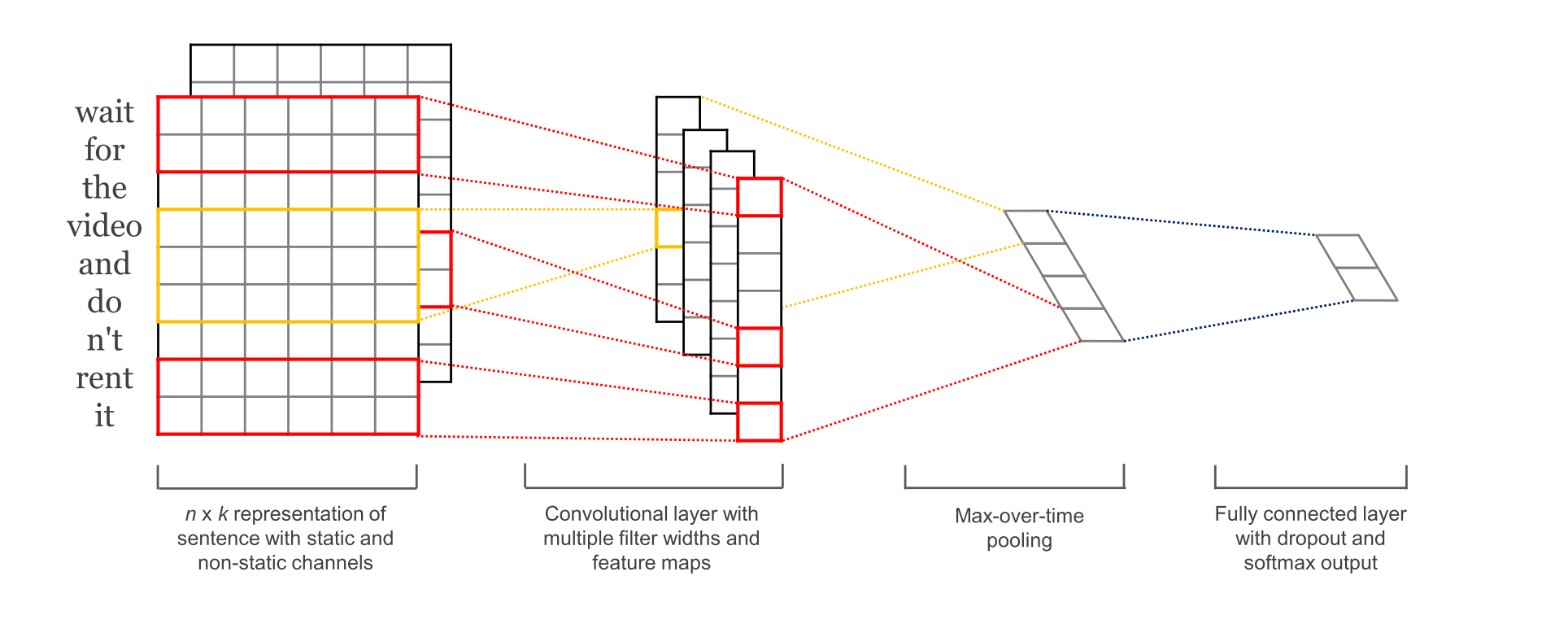
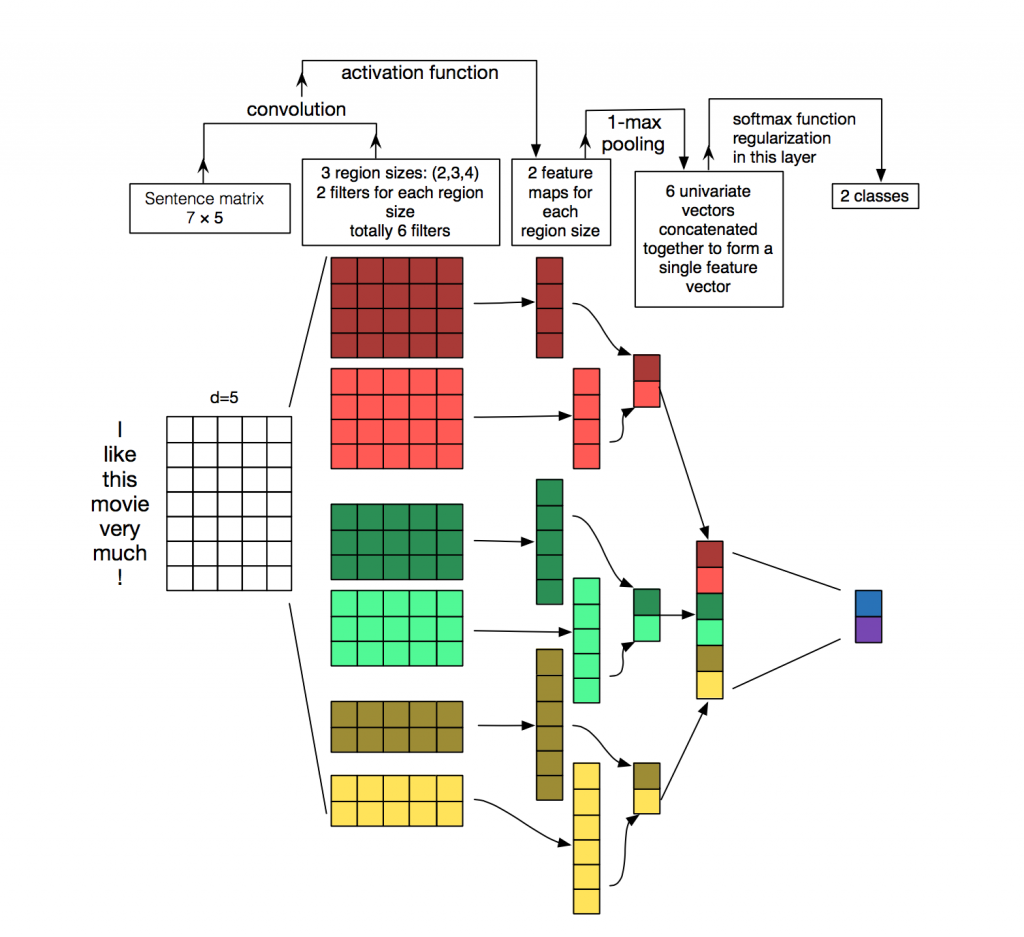
- 这里word embedding的维度是5。对于句子 i like this movie very much。可以转换成如上图所示的矩阵AϵR7×5AϵR7×5
- 有6个卷积核,尺寸为(2×5)(2×5), (3×5)(3×5), 4×54×5,每个尺寸各2个.
- A分别与以上卷积核进行卷积操作,再用激活函数激活。每个卷积核都得到了特征向量(feature maps)
- 使用1-max pooling提取出每个feature map的最大值,然后在级联得到最终的特征表达。
- 将特征输入至softmax layer进行分类, 在这层可以进行正则化操作( l2-regulariation)
TextCNN TensorFlow实现
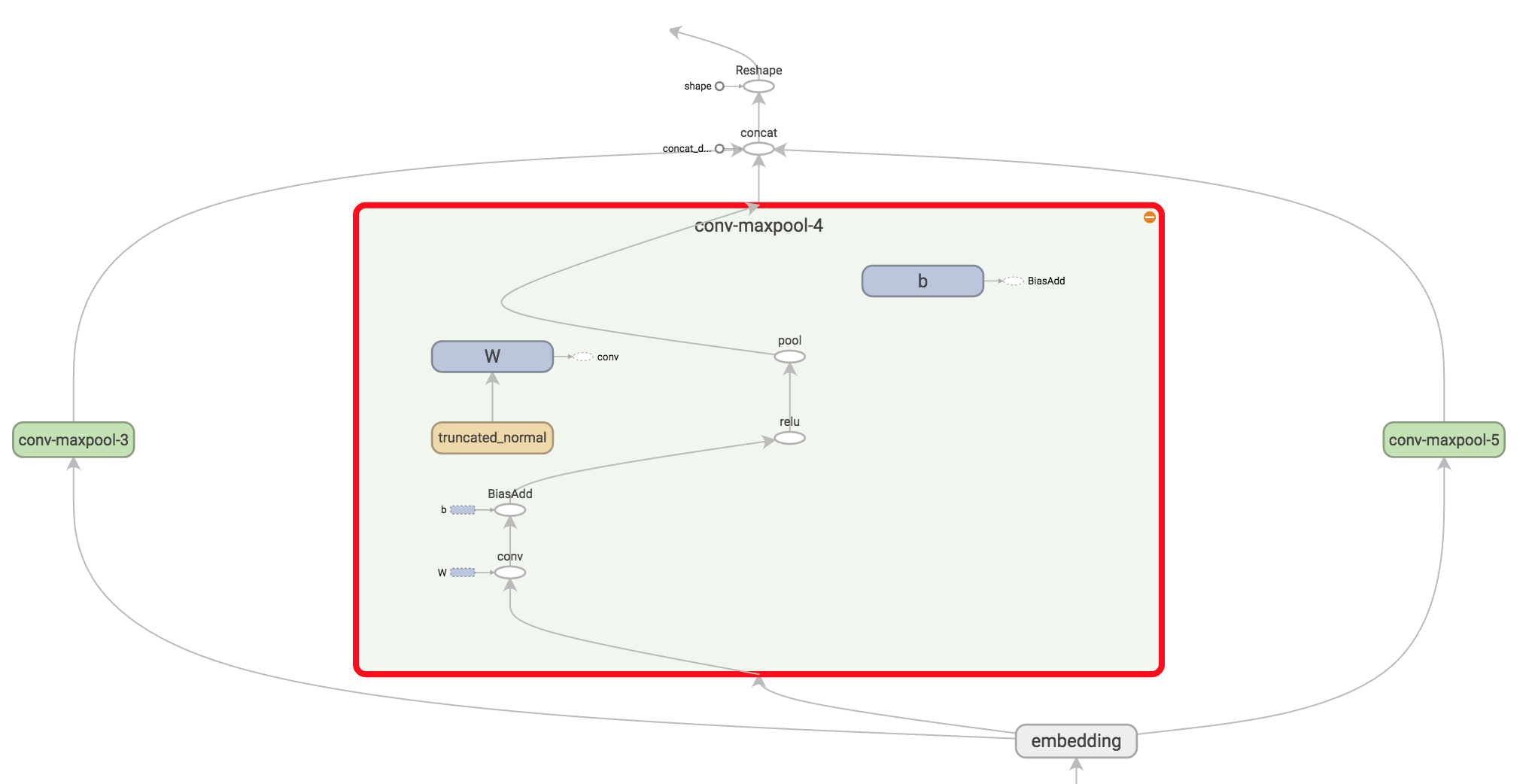
import tensorflow as tf
import numpy as np
class TextCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def __init__(
self, sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
TextCnn的结构
嵌入层(embedding layer)
textcnn使用预先训练好的词向量作embedding layer。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩阵, 里的每一行都是词向量。这个可以是静态(static)的,也就是固定不变。可以是非静态(non-static)的,也就是可以根据反向传播更新
通过一个隐藏层, 将 one-hot 编码的词 投影 到一个低维空间中.
本质上是特征提取器,在指定维度中编码语义特征. 这样, 语义相近的词, 它们的欧氏距离或余弦距离也比较近.
卷积池化层(convolution and pooling)
卷积(convolution)
输入一个句子,首先对这个句子进行切词,假设有个单词。对每个词,跟句嵌入矩阵, 可以得到词向量。假设词向量一共有维。那么对于这个句子,便可以得到行列的矩阵.
我们可以把矩阵看成是一幅图像,使用卷积神经网络去提取特征。由于句子中相邻的单词关联性总是很高的,因此可以使用一维卷积。卷积核的宽度就是词向量的维度,高度是超参数,可以设置。
对一个卷积核,可以得到特征, 总共个特征。我们可以使用更多高度不同的卷积核,得到更丰富的特征表达。
池化(pooling)
不同尺寸的卷积核得到的特征(feature map)大小也是不一样的,因此我们对每个feature map使用池化函数,使它们的维度相同。最常用的就是1-max pooling,提取出feature map照片那个的最大值。这样每一个卷积核得到特征就是一个值,对所有卷积核使用1-max pooling,再级联起来,可以得到最终的特征向量,这个特征向量再输入softmax layer做分类。这个地方可以使用drop out防止过拟合
参数选择
- 初始化词向量
使用word2vec和golve都可以,不要使用one-hot vectors - 卷积核的尺寸
1-10之间,具体情况具体分析,对最终结果影响较大。一般来讲,句子长度越长,卷积核的尺寸越大。 - 每种尺寸卷积核的数量
100-600之间,对模型性能影响较大,需要注意的是增加卷积核的数量会增加训练模型的实践。 - 激活函数的选择
使用relu函数 - drop out rate
0.0-0.5, 当增加卷积核的数量时,可以尝试增加drop out rate,甚至可以大于0.5 - 池化的选择
1-max pooling - 正则项
正则项对最终模型性能的影响很小
与 LeNet 作比较
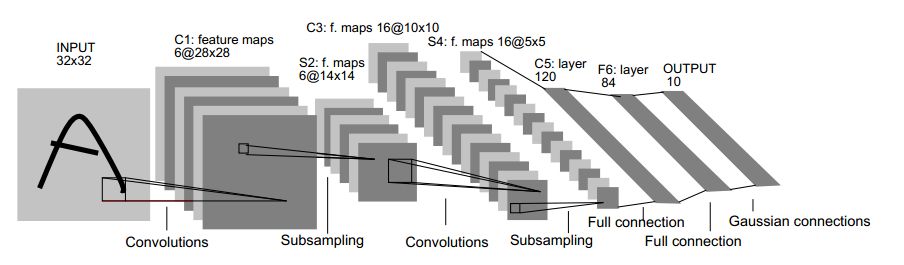 LeNet-5:
LeNet-5:
# LeNet5
conv1_weights = tf.get_variable(
"weight",
[CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.nn.conv2d(
input_tensor,
conv1_weights,
strides=[1, 1, 1, 1],
padding='SAME')
tf.nn.max_pool(
relu1,
ksize = [1,POOL1_SIZE,POOL1_SIZE,1],
strides=[1,POOL1_SIZE,POOL1_SIZE,1],
padding="SAME")
TextCNN:
#TextCNN
conv1_weights = tf.get_variable(
"weight",
[FILTER_SIZE, EMBEDDING_SIZE, 1, NUM_FILTERS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.nn.conv2d(
self.embedded_chars_expanded,
conv1_weights,
strides=[1, 1, 1, 1],
padding="VALID")
tf.nn.max_pool(
h,
ksize=[1, SEQUENCE_LENGTH - FILTER_SIZE + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID')
卷积层
LeNet 的 filter 是正方形的, 且每一层都只用了同一种尺寸的卷积核. Text-CNN中, filter 是矩形, 矩形的长度有好几种, 一般取 (2,3,4), 而矩形的宽度是定长的, 同 word 的 embedding_size 相同. 每种尺寸都配有 NUM_FILTERS 个数目, 类比于LeNet中的output_depth,所以得到的feature_map是长条状, 宽度为1.
因为是卷积, 所以stride每个维度都是1.
池化层
池化处理, 也叫下采样. 这里依旧可以对比 LeNet 网络. LeNet 的 kernel 是正方形, 一般也是2*2等, 所以会把卷积后的feature_map尺寸缩小一半. Text-CNN 的 kernel 依旧是长方形, 将整个feature_map 映射到一个点上. 一步到位, 只有一个池化层.
全连接层
都是多分类, 这一步的处理比较类似. 将池化后的矩阵 reshape为二维, 用 tf.nn.sparse_softmax_cross_entropy_with_logits() 计算损失.
参考资料
Til next time,
gentlesnow
at 14:48
