
【NLP】【CS224N】2.3 word2vec
其他视频参考补充。
word embedding
词嵌入的优点
传统one-hot编码
- 纬度高(几千几万维稀疏向量),数据稀疏
- 难以计算词之间相似度
- 难以做模糊匹配
词嵌入
- 纬度低(100-500维)
- 无监督学习,不需要去掉停用词(stopwords)
- 天然有聚类后的效果
- 连续向量,方便机器学习模型处理
- 处理罕见词 “风姿绰约”=“漂亮”
最早的词嵌入模型
Bgengio 2003, A Neural Probabilistic Language Model
输入:上下文词的向量
输出:下个词的概率
目标:最大化预测概率
两次矩阵乘,两次非线性变换
参数多,容易过拟合
优化缓慢,不适合大语料
上下文的向量(Vw1, Vw2, …, Vwc-1) -> 乘矩阵H(参数矩阵) -> Tanh变换 -> 乘矩阵U(参数矩阵) -> softmax变换为概率 -> P(wc = i)
Word2Vec
Mikolov 2013, Distributed Representations of Words and Phrases and their Compositionality
使用最广泛的词嵌入方法
速度快,效果好,容易扩展
原因:简单(Less is more)
回归连接函数:
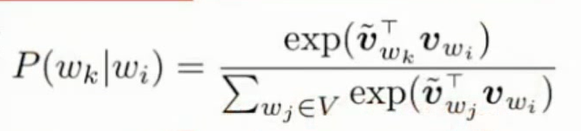
没有耗时的矩阵乘,只留有一个softmax变换
有些维代表语法,有些维代表语义
优化算法:SGD
每次扫描一个词,算一下梯度,更新……
收敛很快。大语料:1、2个pass,小语料:10个pass
Negative sampling:近似分母(归一化系数)的梯度,提高效率
Hierarchical softmax: 提高效率,效果略差
exp(VwkT, Vwi)对数双线性(log-bilinear)方法
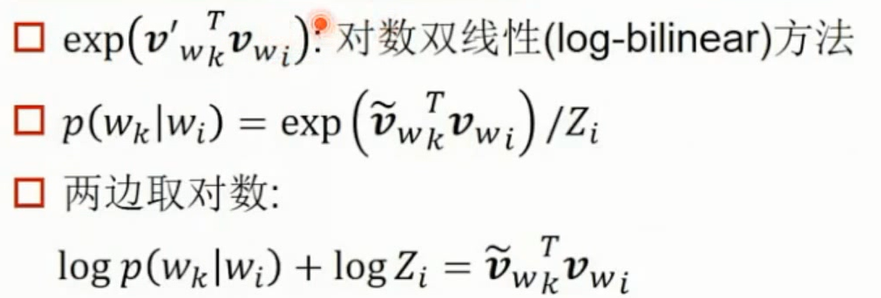
word2vec和矩阵分解的等价性
Levy 2014, l
Word2Vec理论上等价于分解Pointwise Mutual Information(PMI)矩阵

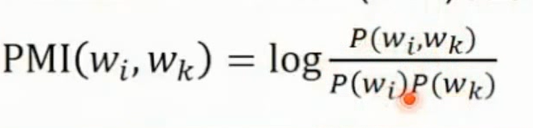
GloVe 矩阵分解求词嵌入
不同算法性能比较
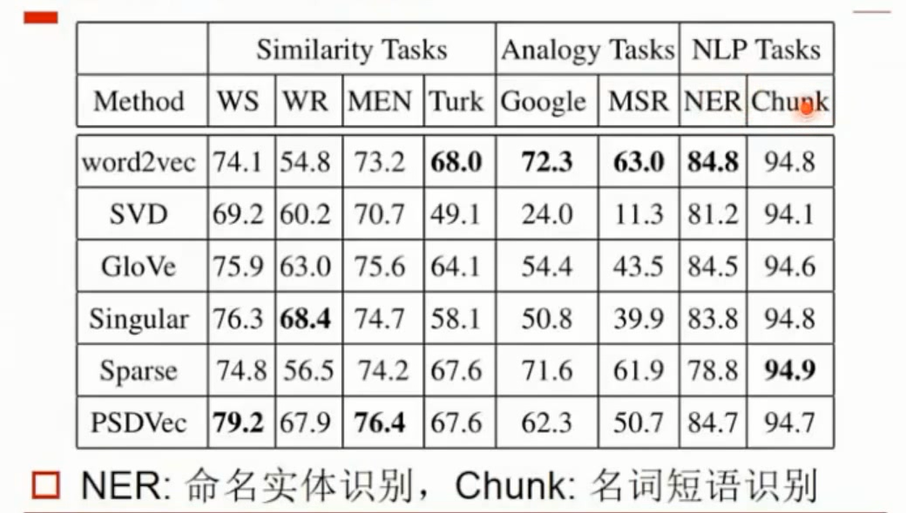
影响词嵌入效果的因素
- 预料大小,预料与应用是否在同一领域
- 向量维度:预料大->维度大。过大容易过拟合
- 上下文窗口:3~7 过小:捕捉模式太少 过大:噪音太多 有加权:窗口可能大一些
- Word2Vec特有的参数
- iteration:预料大->迭代次数少
- Negative sampling:适中,如5~10
“多词义”词嵌入
为每个词义学习单独的词向量
是数据更加稀疏(引入噪音)
多词义,单向量 = 不同词向量的加权和
Jiwei Li, 2015. Do Muti-Sense Embeddings Improve Natural Language Understanding?
多词义向量的好处,大多可以通过提高向量维度来达到
词嵌入的软件实现
Word2vec, c语言实现
Gensim, python实现,接口多
DL4J,Deep Learning for java
分词软件 jieba
Til next time,
gentlesnow
at 14:48
