
16 Nov 2018
【NLP】【CS224N】3 高级词向量表示
- 完成word2vec
- word2vec真正捕捉到了什么
- 更加有效的捕捉word2vec的本质
- 分析词向量
复习word2vec的主要思路
- 遍历整个语料库中的每个词
- 预测每个词的上下文
- 在每个窗口中计算梯度做SGD
基于共现次数的词向量
Word2Vec根据每次捕获一个单词之间的共现(co-occurrence)信息,并以此更新词向量。例如,在浏览语料库时发现“deep”和“learning”共现了一次,然后我们通过计算更新这两个词的词向量,之后我们继续浏览发现“deep”和“learning”又共现了一次,然后我们再次更新词向量。但是我们仔细一想就可以发现,这样效率似乎并不高,为什么我们不一次找到所有“deep”和“learning”共现的情况呢?事实上的确有这样的方法,而且这种方法要比Word2Vec更早提出。
这些基于共现次数的方法,首先会浏览整个语料库,统计共现次数,再通过共现次数矩阵来获取词向量。考虑共现时,我们通常有两种做法:
- 考虑一定窗口大小内的单词共现,与Word2Vec类似。这种方法不仅能够获得一定的语义信息,同时也能得到一些语法(syntactic)信息,比如动词和动词会比动词和名词更加相似。
- 考虑整篇文档内的单词共现。潜在语义分析(Latent Semantic Analysis, LSA)就是基于文档内的单词共现的,这种方法会忽略单词的语法和语义信息,最终得到的是文档大致的话题(topic)信息。这种方法不是我们这节课要讲的,有兴趣的同学可以去了解话题模型(topic model)的相关知识。
接下来我们通过一个简单的例子来了解基于窗口的共现矩阵。假设我们有一个很简单的语料库,其中有下面几个句子:
- I like deep learning.
- I like NLP.
- I enjoy flying.
我们考虑一个简单的情况:窗口大小为1,即考虑每个单词左边和右边的一个单词。比如“I”左边没有单词,而右边的单词有“like”和“enjoy”,其中和“like”共现2次,和“enjoy”共现1次。对于“like”则和“I”共现2次,和“deep”共现1次、和“NLP”共现1次。对于语料库中每个单词进行计数,就可以得到如下单词共现矩阵。
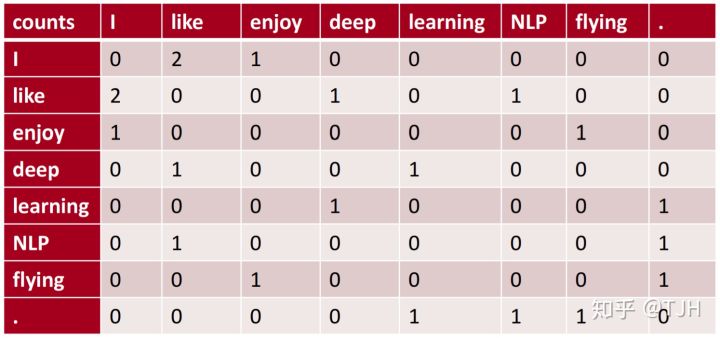
这时如果我们把每行(或每列)当作一个向量,其实就是一种简单的词向量了。但这样的向量会遭遇和独热编码类似的维度和稀疏性问题。这时我们就想到要给这个矩阵降维,那么一个简单的方法就是用奇异值分解(Singular Value Decomposition, SVD)。
使用python来解SVD很简单,只需要几行代码:
import numpy as np
la = np.linalg
words = ["I", "like", "enjoy", "deep", "learning", "NLP", "flying", "."]
X = np.array([[0,2,1,0,0,0,0,0],[0,2,1,0,0,0,0,0],[0,2,1,0,0,0,0,0],\
[0,2,1,0,0,0,0,0],[0,2,1,0,0,0,0,0],[0,2,1,0,0,0,0,0],\
[0,2,1,0,0,0,0,0],[0,2,1,0,0,0,0,0]])
U, s, Vh = la.svd(x, full_mattrices=False)
GloVe
evaluate word vectors
- intrinsic
- evaluation on a specific/intermediate subtask
- Fast to compute
- Helps to understand that system
- Not clear if really helpful unless correlation to real task is established
- extrinsic
- Evaluation on a real task
- Can take a long time to compute accuracy
- Unclear if the subsystem is the problem or its interaction or other subsystems
- If replacing exactly one subsystem with another improves accuracy Winning!
参考笔记:
Til next time,
gentlesnow
at 10:08
