
【NLP】【DeepMind】1 Word Vector and Lexical Semantics
Natural language text(自然语言文本) = sequences od discrete sysbols(e.g. words)
Naive representation: one hot vectors(独热向量) in $R^{|vocabulary|}$ (very large)
Classical IR:document and query vectors are superpositions of word vectors.
Similarly for word classification problems(e.g. naive bayes topicmodels(主题模型))
Issues:sparse(稀疏), orthogonal representations, semantically weak.
richer representations expressing semantic Similarly.
Idea: produce dense vector representations based on the context/use of words.
Three main approaches:
- count-based(基于计数的)
- predictive(预测性的)
- task-based(任务型的)
count-based methods
- Define a basis vocabulary C of context words.
- Define a word window size w.
目的是将跟目标语义不相关的单词移除窗口。 - Count the basis vocabulary words occurring w words to the left or right or right of each instance of a target word in the corpus.(统计在目标词汇的两侧窗口(w的词距)中基本词出现的次数)
- From a vector representation of the target word based on these counts(并将这个数量表示为矢量).
- Use inner produce or cosine as similarly kernel.(e.g. cosine)
cosine has the advantage that it’s a norm-invariant metric.
issues:not all features are equal
Many normalization methods(来自于统计学的适量标准化方法): TF-IDF, PMI, etc.
Some remove the need for norm-invariant similarly metrics.
Neural Embedding models(神经词向量模型)
Learning count based vectors produces an embedding matrix in $R^{|vocabulary|}$
raw = word vectors
symbols = unique vectors
representation = embedding symbols with E
one generic idea behind embedding learning:

- collect insatnces
- for each instance, collect it’s context words
- define some score function score with upper bound on output
- define a loss
easy to design a useless scorer(e.g. ignore input, output upper bound).
ideally, score:
- embeds t with E(obviously).评分函数要明显的用到优化后的词向量矩阵t,并得到一个表征。
- produces a score which is a function of how well t is accounted for by c.得出的分数要有说明性。
- requires the word to account for the context (or the reverse) more than another word in the same place.评价上下文可以将单词解释的怎么样,反映在自然语言中的使用情况怎么样。
- produces a loss which is differentiable w.r.t. theta and E.
- estimate E
- use the estimate E as your embedding matrix
paper: Natural Language Processing (Almost) from Scratch
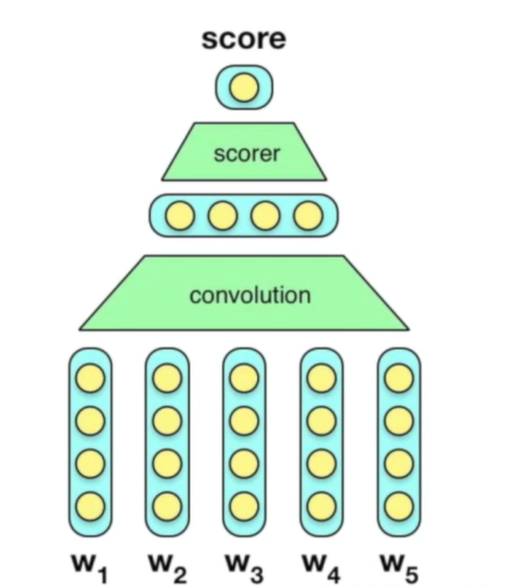
C&W model
 ?
?
paper: Mikolov et al. 2013
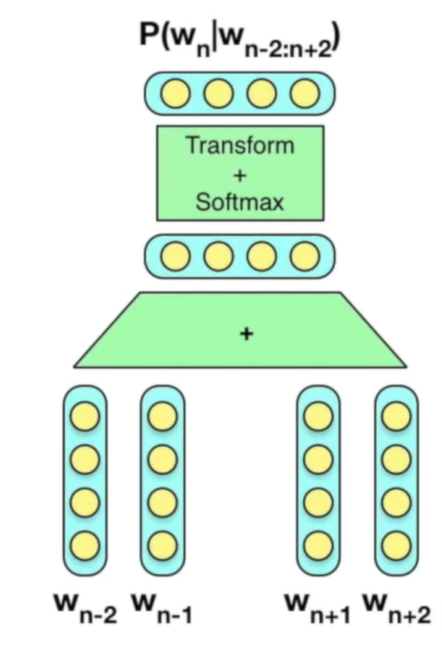
CBoW model
 ?
?
Til next time,
gentlesnow
at 11:02
