
【论文研读】 005 BAMnet
论文地址: https://arxiv.org/pdf/1903.02188.pdf
作者:
Yu Chen Rensselaer Polytechnic Institute
Lingfei Wu IBM Research
Mohammed J. Zaki Rensselaer Polytechnic Institute
论文动机/背景
当前的基于知识库的问答系统忽视了问题和知识库的细微关系。 例如实体类型、关系路径和上下文。
随着大规模知识库的发展(DBPedia、FreeBase),KBQA试图从给出的问题中通过知识库自动地找到答案。
KBQA的一个重大的挑战就是词汇空缺(lexical gap)。 一个相同的问题在自然语言中有不同的方式表示,而在KB中则使用专业的词汇。 解决这个问题的方法有两种:语义理解SP和信息检索IR。
基于SP的方法通过构造语义解析器来解决该问题,该语义解析器将NL问题转换为中间逻辑形式,其可以针对KB执行。 传统的语义分析器需要使用常规逻辑形式作为监督,并且仅限于具有少量逻辑谓词的窄域。 最近的论文通过构建手工制作的规则或特征模式匹配以及使用来自外部资源的弱监督来克服这些限制。
基于SP的方法通常预先设计词汇触发器和规则,这限制了它的领域和可伸缩性。 基于IR的方法直接从KB中检索答案。 因为不需要手工的规则,能在长和混合的KB中表现得更好。
目前深度学习在这个领域也取得了不错的结果。 目前的思路是采用各种方法将问题和KB子图编码到一个共同的嵌入空间中, 并在该空间中直接匹配它们,并且通常可以以端到端的方式进行训练。
论文贡献
论文设计了一个模型BAMnet,对知识库和问题的两个交互流进行建模。 这个模型可以捕获问题与底层KB之间的相互作用,存储在内容可寻址存储器中。
在WebQuestions基准测试中,不需要外部资源,只需要少量手工特征, BAMnet显着优于现有的基于信息检索的方法,并且对基于语法分析的(手工制作)方法拥有竞争力。 由于使用注意力机制,与其他基线相比,这个模型有更好的可解释性。
论文的贡献:
- 为KBQA的任务提出了一种双向注意力记忆网络,旨在直接模拟问题与KB之间的双向交互
- BAMnet通过注意机制提供了良好的可解释性
- 在We-bQuestions基准测试中,BAMnet明显优于以前的基于信息检索的方法,同时保持基于语义分析的方法的竞争。
最近相关的研究工作
基于SP的方法试图将NL问题转换为逻辑形式。 最近的工作重点是基于外部资源,模式匹配或使用手工制作的规则和功能的弱监督的方法。 研究的一个方面是从NL问题生成语义查询图, 例如使用短语和谓词之间的粗略对齐,通过agenda-based的策略查询部分的逻辑形式, 在查询评估阶段加入消岐, 或者利用NL问题中的丰富的句法信息。
基于SP的方法的另一个研究方向是借助神经网络的答案预测模型再通过计算两个序列特征的相似度来得到答案,或者通过强化学习来训练一个端到端的神经符号机器。
大多数基于SP的方法或多或少都依赖于手工制作的规则或功能,这限制了它们的可扩展性和可转移性。
基于IR的方法工作重点是将答案和问题映射到相同的嵌入空间,人们可以独立于其架构查询任何KB,而无需任何语法或词典。
Bordes是第一个为KBQA应用嵌入式方法的人。 Bordes提出了子图嵌入的概念,它对备选答案的更多信息(例如,答案路径和上下文)进行编码。 记忆网络用于存储备选答案,并且可以迭代地访问来模仿多跳推理。 它不使用词袋(BOW)表示来编码问题和KB资源同,使用更高级的网络模块(例如,CNN和LSTM)来编码问题。
Hao提出了一种交叉注意机制,以根据各种候选答案方面对问题进行编码。 论文的方法更进一步,通过建模问题和KB之间的双向交互来编码。
与双向注意力在机器阅读理解上的应用相比,BAMnet更专注与文本与KB之间的相互作用。
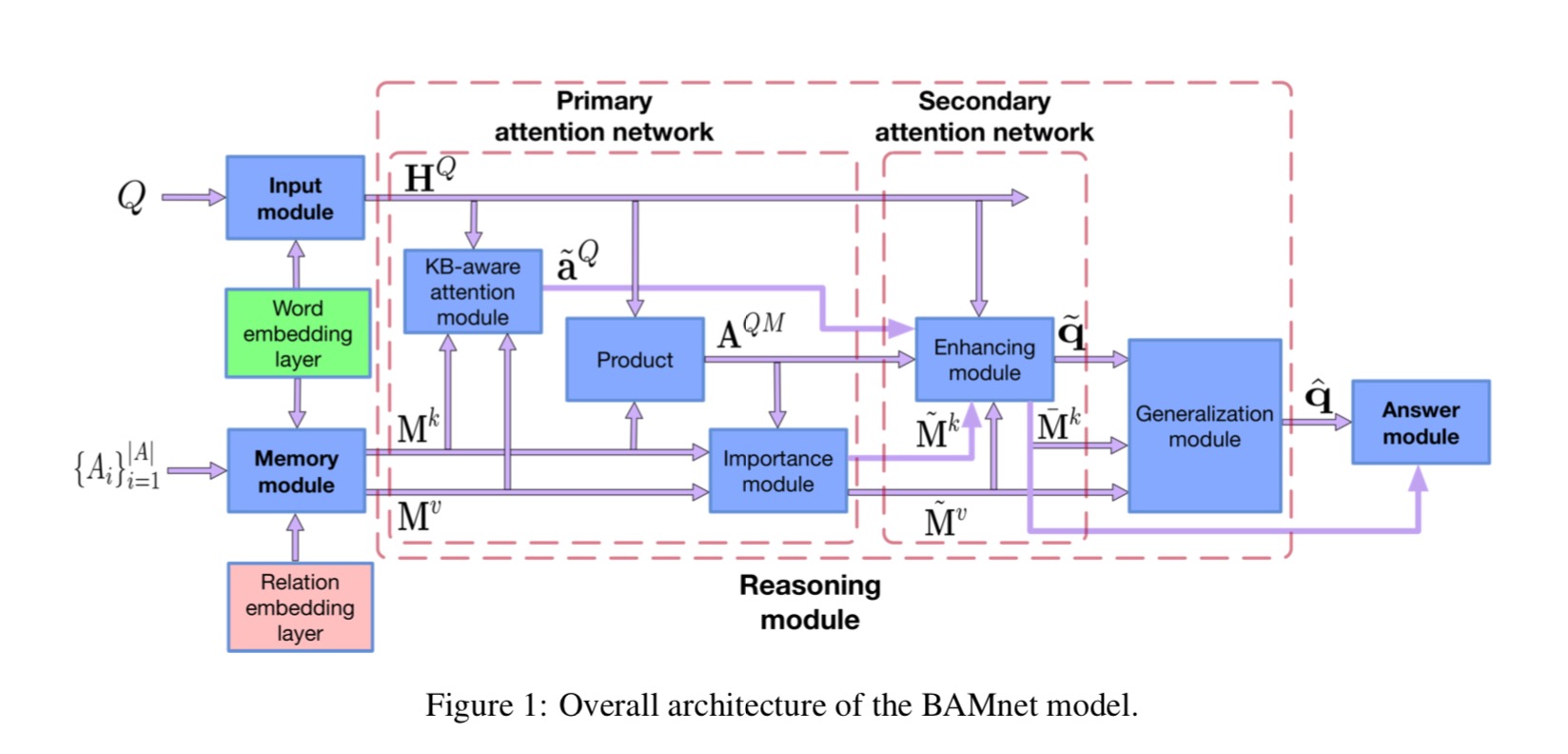
模型结构
这是个双向注意力网络模型。 前一个注意力网络倾向于根据KB关注问题的重要部分,或者根据问题关注KB的关键部分。 在此基础上,后一个注意力网络通过进一步利用双向注意力来试图增强问题和KB的表示。 通过这种分层双向关注的思想,这个模型能够提取能够回答在问题和KB附近的问题回答的知识。
Til next time,
gentlesnow
at 20:13
