
【NLP】【CS224N】2.1 word2vec
来自S的视频。
N-gram模型
假设下一个词的出现依赖它前面的一个词:
p(s)=p(w1,w2,w3,w4,…,wn)
=p(w1)p(w2|w1)p(w3|w2)…p(wn|wn-1)
假设下一个词的出现依赖它前面的两个词:
p(s)=p(w1,w2,w3,w4,…,wn)
=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|wn-2,wn-1)
在实际问题中,并不指定跟前面所有的词都相关,而是只与前n个词相关。
即N-gram模型
解决了参数空间过大的问题。
假设词典的大小是N,则模型参数的量级是(O(N^n))
词向量
word2vec
神经网络模型
input layer –> projection layer –> hidden layer –> output layer
训练样本:(context(w),w)包括前n-1个词分别的向量,假定每个词向量大小m
投影层:(n-1) * m 首尾拼接起来的大向量
输出:yw=(yw1,yw2,…,ywN)^T
表示上下文context(w)时,下一个词恰好为词典中第i个词的概率
归一化:p(w|context(w))=(e^(yw,iw)/(Σe^(yw,i)))
神经网路模型的优势:
对于N-gram模型:p(S1)»p(S2)
对于神经网络模型:p(S1)=p(S2)
对与几个相近的句子
只要语料库中出现其中一个,其他句子的概率也会相应的增大。
Hierarchical Softmax
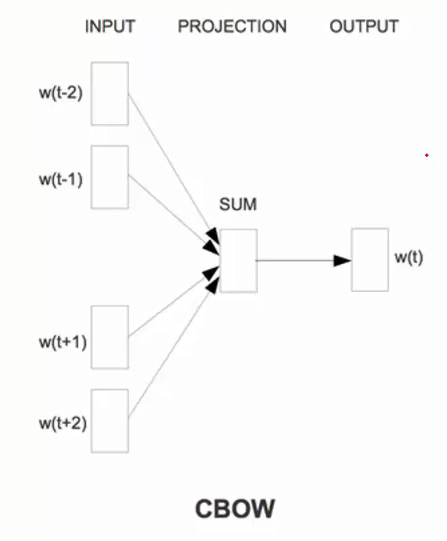
CBOW是Continuous Bag-of-Words Model的缩写,是一种根据上下文的词语预测当前词语出现概率的模型。
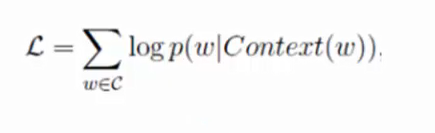
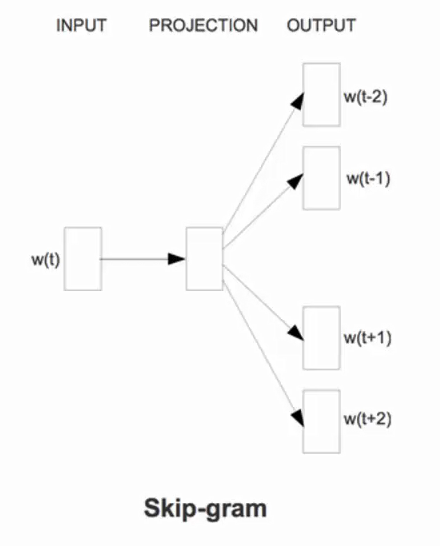
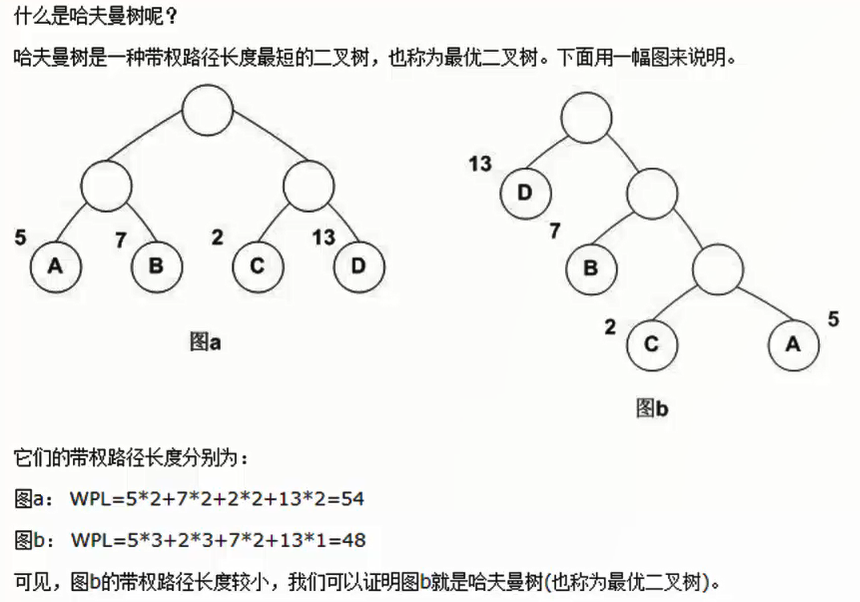
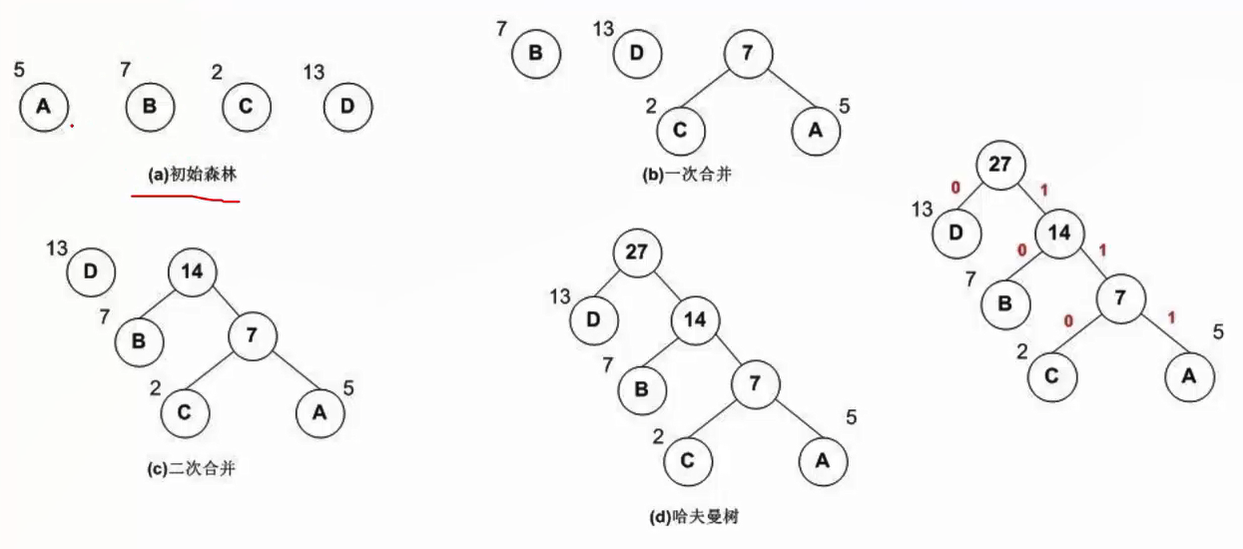
哈夫曼树:
Logistic回归:
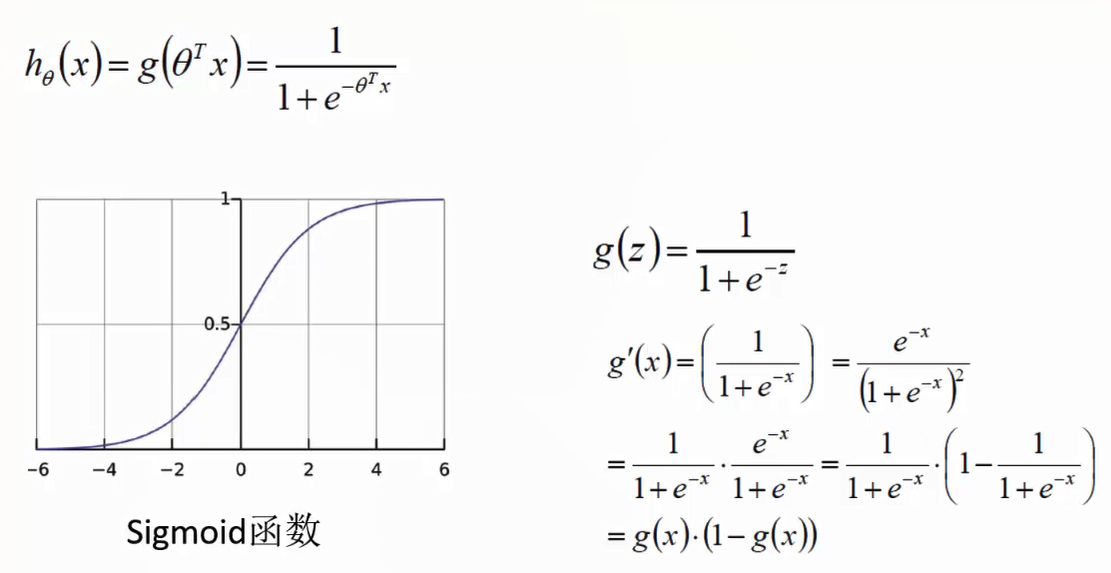
Softmax相当于一个多分类的逻辑斯蒂回归。
CBOW:
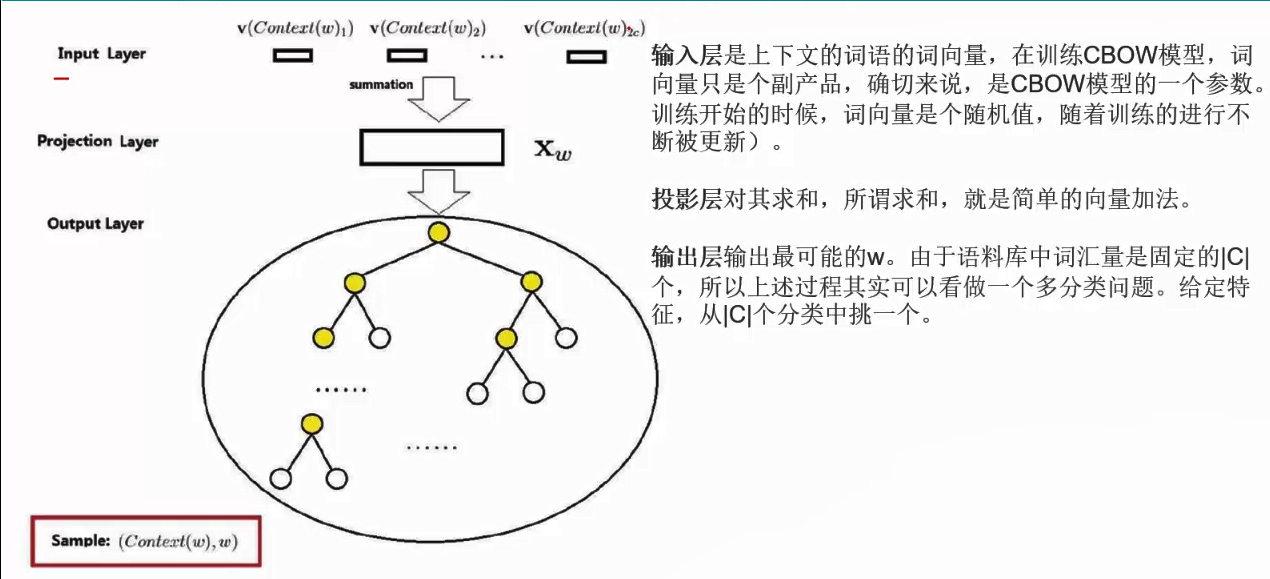
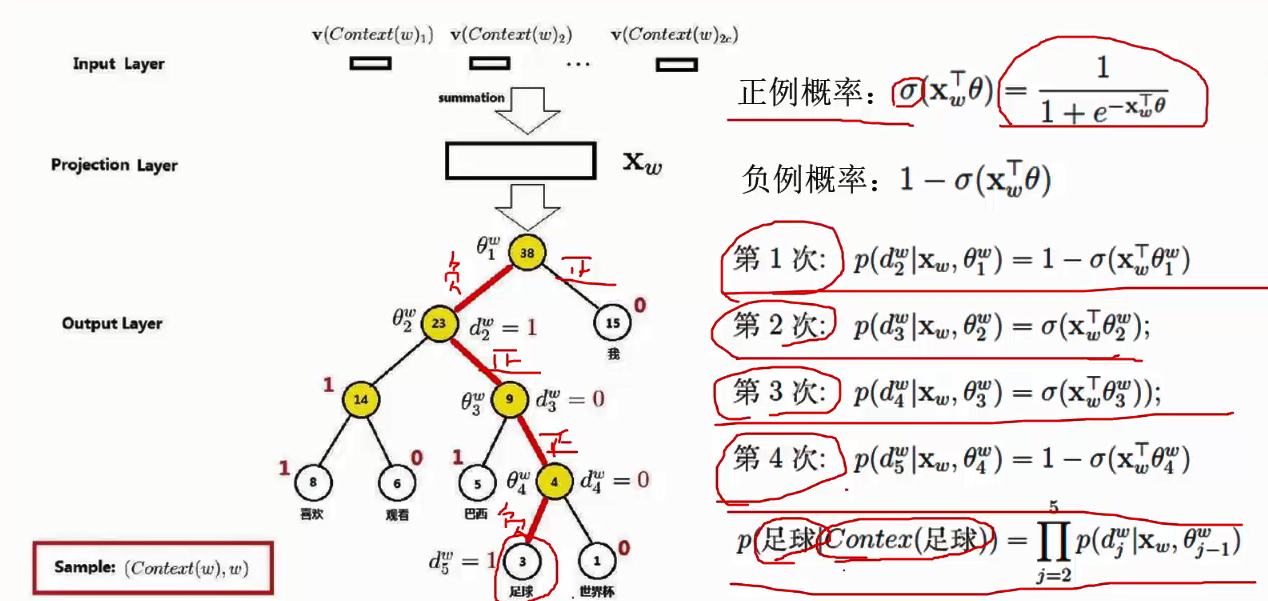
CBOW的更新。
Negative Sampling
任何采样算法都应该保证频次越高的样本越容易被采样出来。
基本思路是,对于长度为1的线段,根据此语的词频,将其公平的分配给每个词语。
感觉讲的很简略,还是看cs224n吧。
等买的书到了,配合书来学,效果应该会好一点。
Til next time,
gentlesnow
at 19:42
