
【NLP】【CS224N】2.2 word2vec
由于之前的视频看的很仓促,有很多没有总结到。甚至于后面的部分完全没看懂,再重新看一遍。
一来是语言,即使加上中文字幕还是学的很勉强。
二来前面学的很仓促,需要补充的有点多。
所以整个进度会很慢。
这也是没办法的事。
学习计划:
- word meaning 词义
- word2vec introduction 介绍word2vec词汇向量模型
- research highlight
- word2vec objective function gradients
- optimization refresher
- assignment 1 notes
- usefulness of word2vec
如何表示词义
目前最常用的方法:用分类资源来处理词义。
对于英语而言,最有名的分类资源就是WordNet。
存在着大量的同义词资源,但是很难从这些资源中尽可能多的获取价值。
细微的差别很难区分。
一些比喻性的表达,wordnet中找不到。
很难对词义的相似性给出准确的定义。
–离散化表征或分类学表征普遍存在的问题
几乎所有的NLP研究,除了现代深度学习,以及80年代做的一点NLP神经网络以外,其他所有的NLP都使用了原子符号来表示单词。
如果从神经网络的角度来考虑这个问题,那么使用原子符号就像使用只有一个位置是1,其他全是0的大向量。
这样就有了大量与原子符号相对应的词汇。
而这样的向量会非常长。
–>神经网络的独热码(one-hot)
独热词汇向量是一种存储在某处的本地表示。
分布相似性 (distributional similarity) 只需观察一个词出现的上下文,就可以找大量词来表示这个词的含义。
为每个单词建立一个密集向量,让他可以预测目标单词所在文本的其他词汇。
什么是word2vec
一种解决学习神经词嵌入问题的通用方法。
定义一个模型,根据中心词汇预测它上下文的词汇。
用一些概率方法根据给定单词预测上下文单词出现的概率。
再用损失函数来判断预测的准确性。
目标是调整词汇表示,从而使损失最小化。
低维向量表示(low-dimensional word vectors):
word2vec模型的核心是构建一个很简单的、可扩展的、快速的训练模型,从而可以处理数十亿单词的文本,并生成非常棒的单词表示。
word2vec尝试去做的最基本的事情就是利用语言的意义理论,来预测每个单词和它的上下文。
word2vec中存在两个用于生成词汇向量的算法:
- Skip-grams(SG)
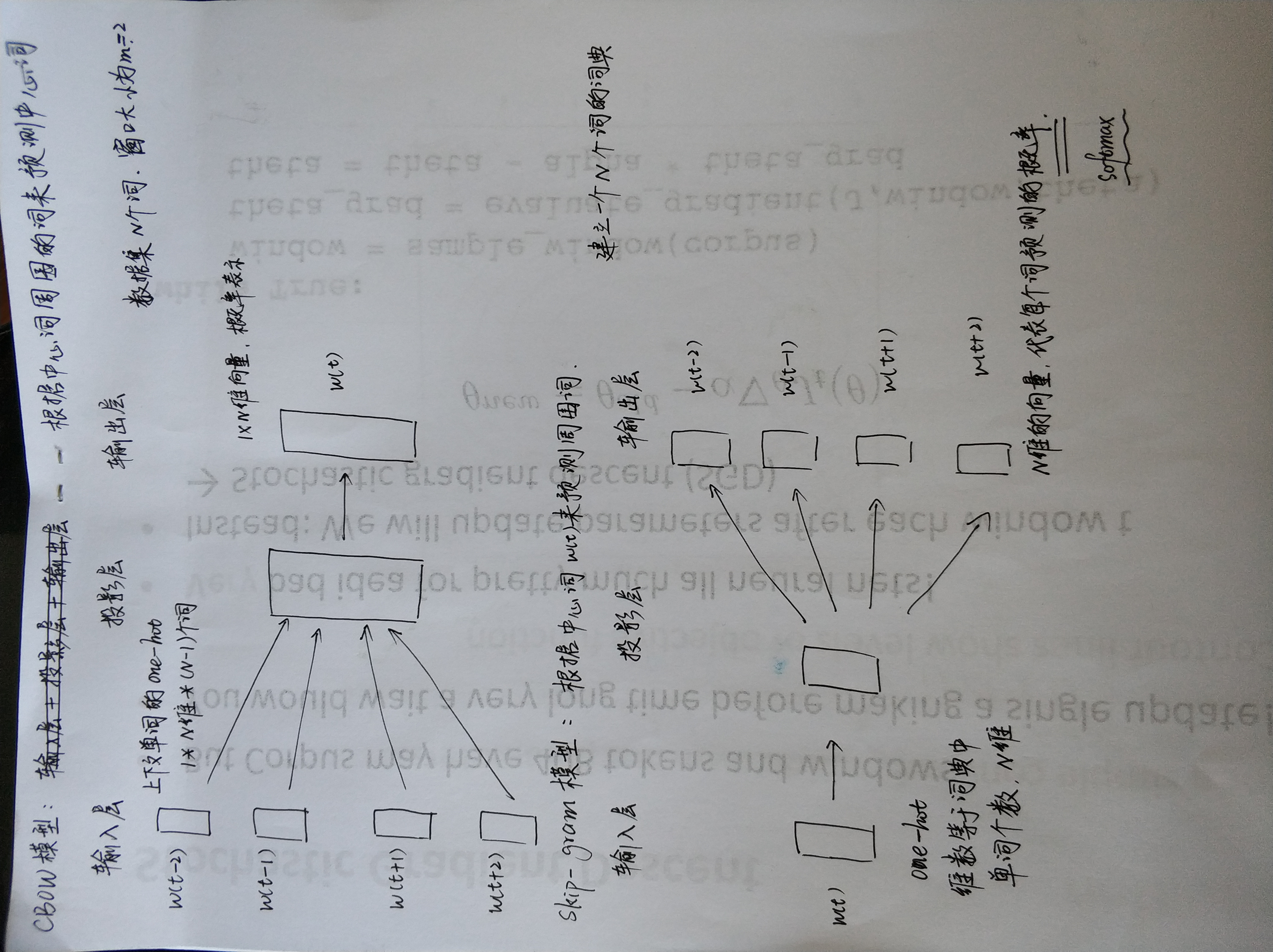
- Continuous Bag of Words(CBOW)
这两个算法效率较低。
两个高效的训练算法:
- Hierarchical softmax
- Negative sampling
任务:实现其中一个高效训练算法。
Skip-gram
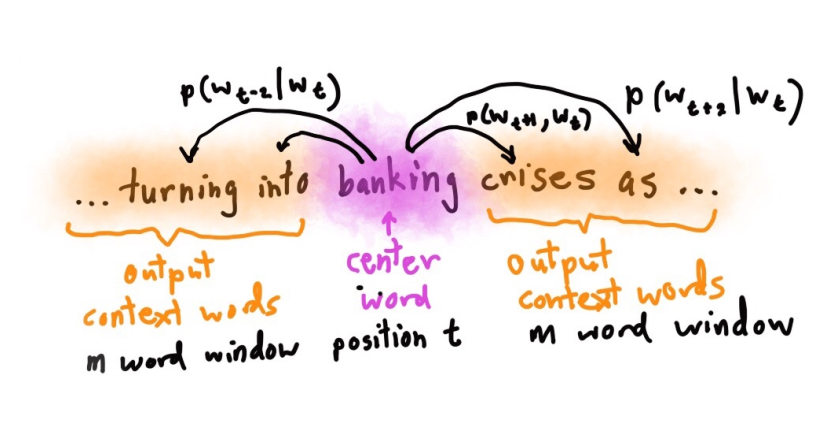
中心词汇(独热向量)–>
在每一个估算步都取一个词作为中心词汇。
这个模型将定义一个概率分布,即给定一个中心词汇,某个单词在他上下文出现的概率。
选取词汇的向量表示,以让概率分布最大化.
这个模型只有一个概率分布,即对于一个词汇有且仅有一个概率分布。
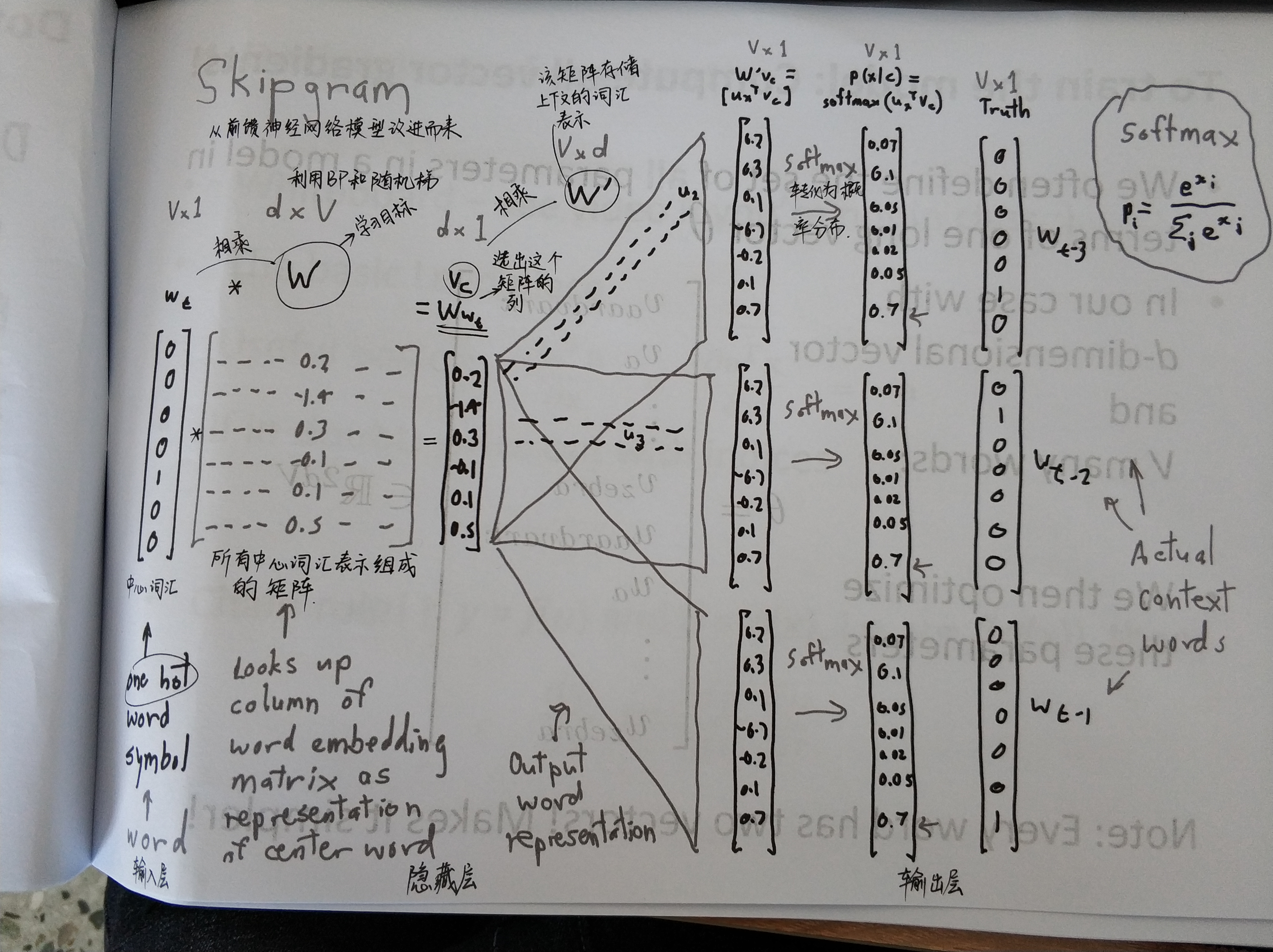
从左到右是one-hot向量,乘以center word的W于是找到词向量,乘以另一个context word的矩阵W’得到对每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。
定义一个半径m,从中心词开始到距离为m的位置,来预测周围的词。
CBOW
CBOW 是 Continuous Bag-of-Words Model 的缩写,是一种根据上下文的词语预测当前词语的出现概率的模型。
训练模型
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov
arXiv:1301.3781v3 [cs.CL] 7 Sep 2013
Til next time,
gentlesnow
at 14:48
