
【西瓜书】 003 线性模型
第三章 线性模型
线性模型(linear model)试图通过学得一个通过属性的线性组合来进行预测的函数,即
\[f(x) = w_1 x_1 + w_2 x_2 + ... + w_d x_d +b\]向量形式为
\[f(x) = W^T x + b\]其中$W = (w_1; w_2; …; w_d)$
线性回归(Linear Regression)
给定数据集$D = {(x_1, y_1), (x_2, y_2), …, (x_m, y_m)}$ ,其中$x_i = (x_{i1}; x_{i2}; …; x_{id})$,$y_i \in \mathbb{R}$.线性回归试图学的一个线性模型以尽可能准确地预测实值输出标记.
$f(x_i) = w x_i + b$,使得$f(x_i) \backsimeq y_i$
考虑单个属性的情况:

向量形式:
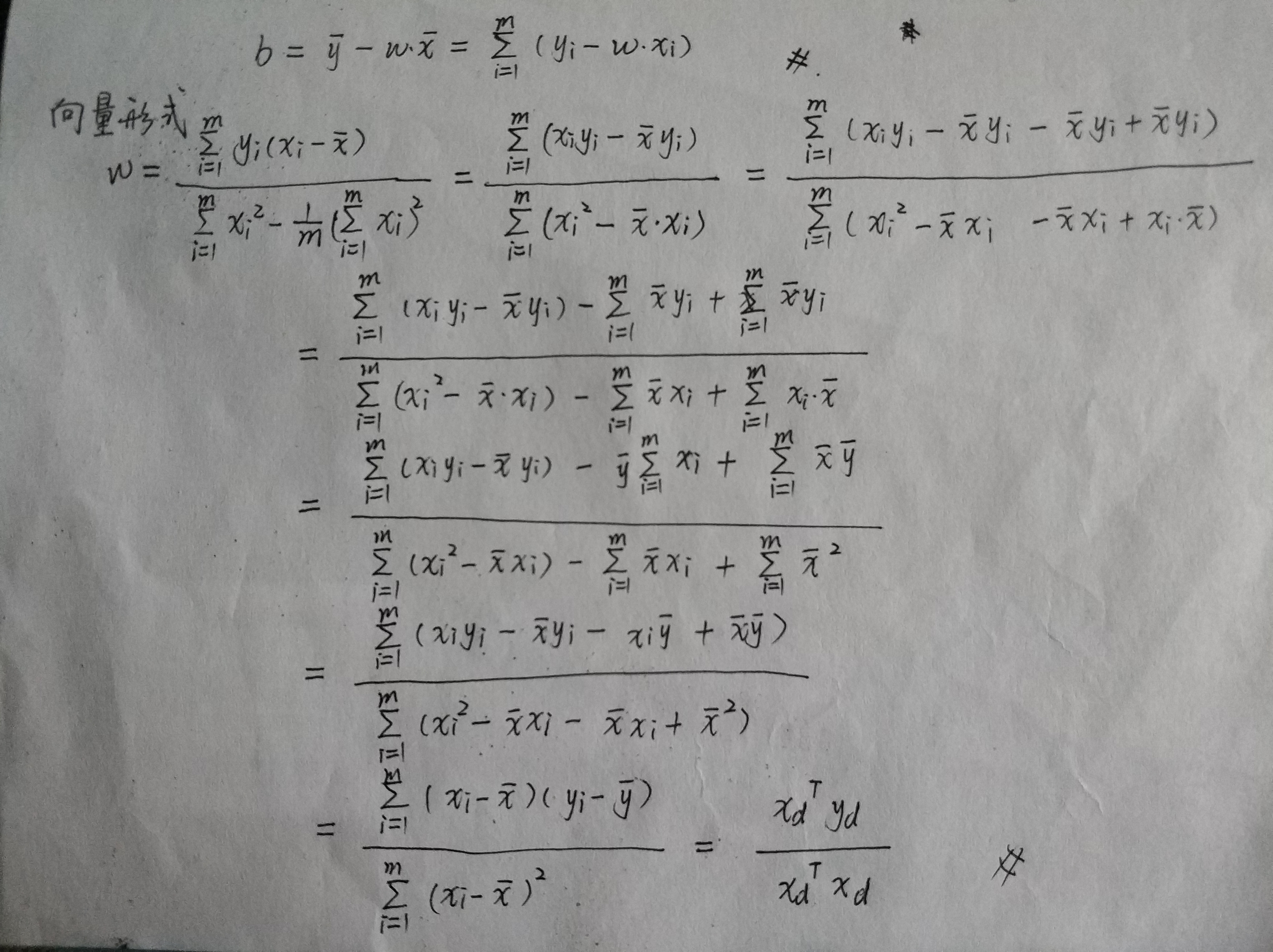
多个属性的情况:

现实任务中$X^T X$往往不是满秩矩阵,许多任务中属性数目会超越样例数目,此时会有多个解均能使均方误差最小化.选择哪个解将由学习算法的偏好决定,常见的做法是引入正则化项.
对数线性回归: \(\ln y = w^T x + b\)
$g(.)$联系函数,单调可微.广义线性模型: \(y = g^{-1}(w^T x + b)\)
对数线性回归是广义线性模型的特例.
逻辑回归(Logistic Regression)

根据凸优化理论,经典的凸优化算法梯度下降法、牛顿法都可以求得最优解:
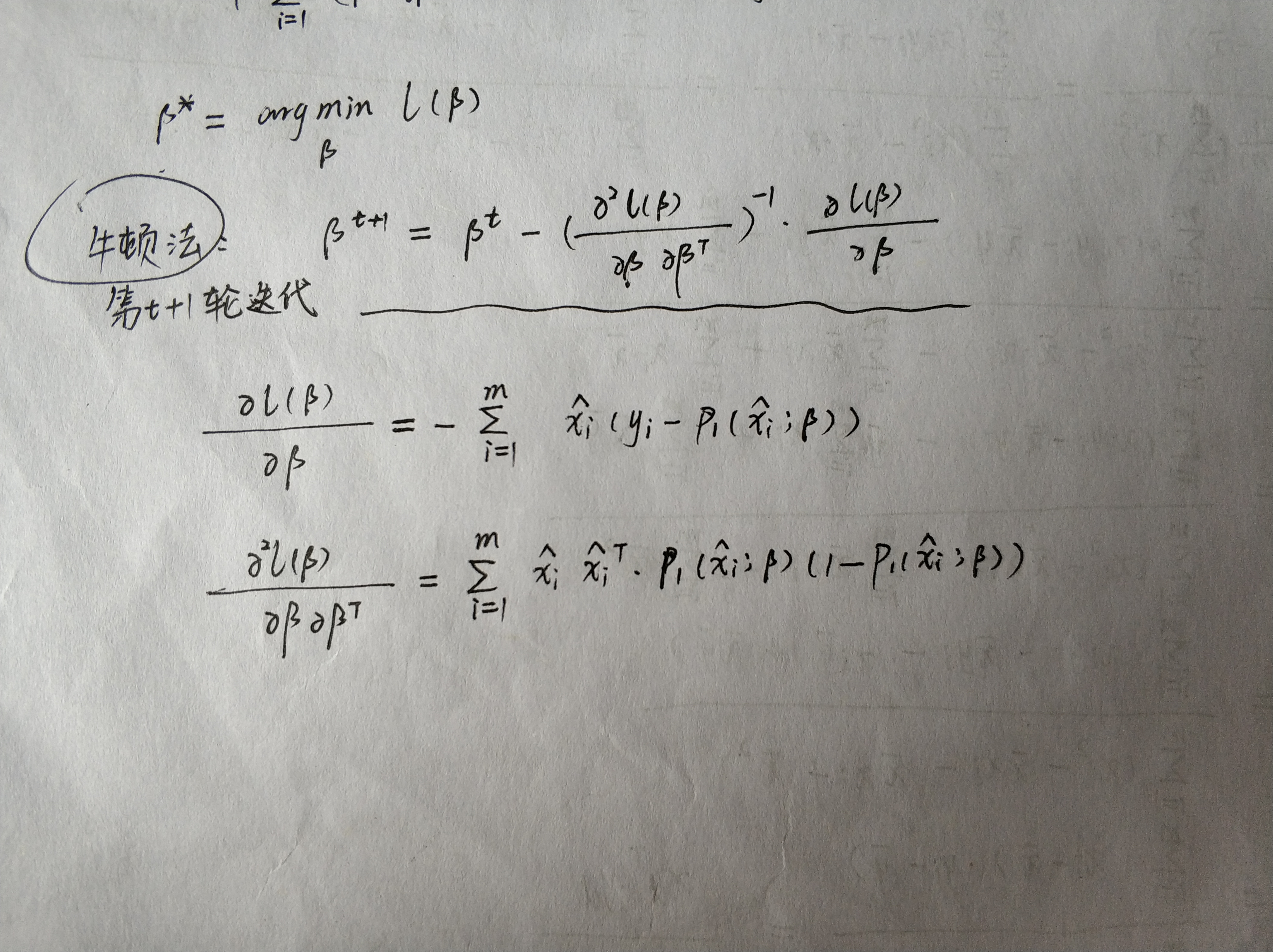
线性判别(LDA)
LDA的思想非常朴素:给定训练数据集,设法将样例投影到一条直线上使得同类样例的投影点尽可能接近、异类投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别.

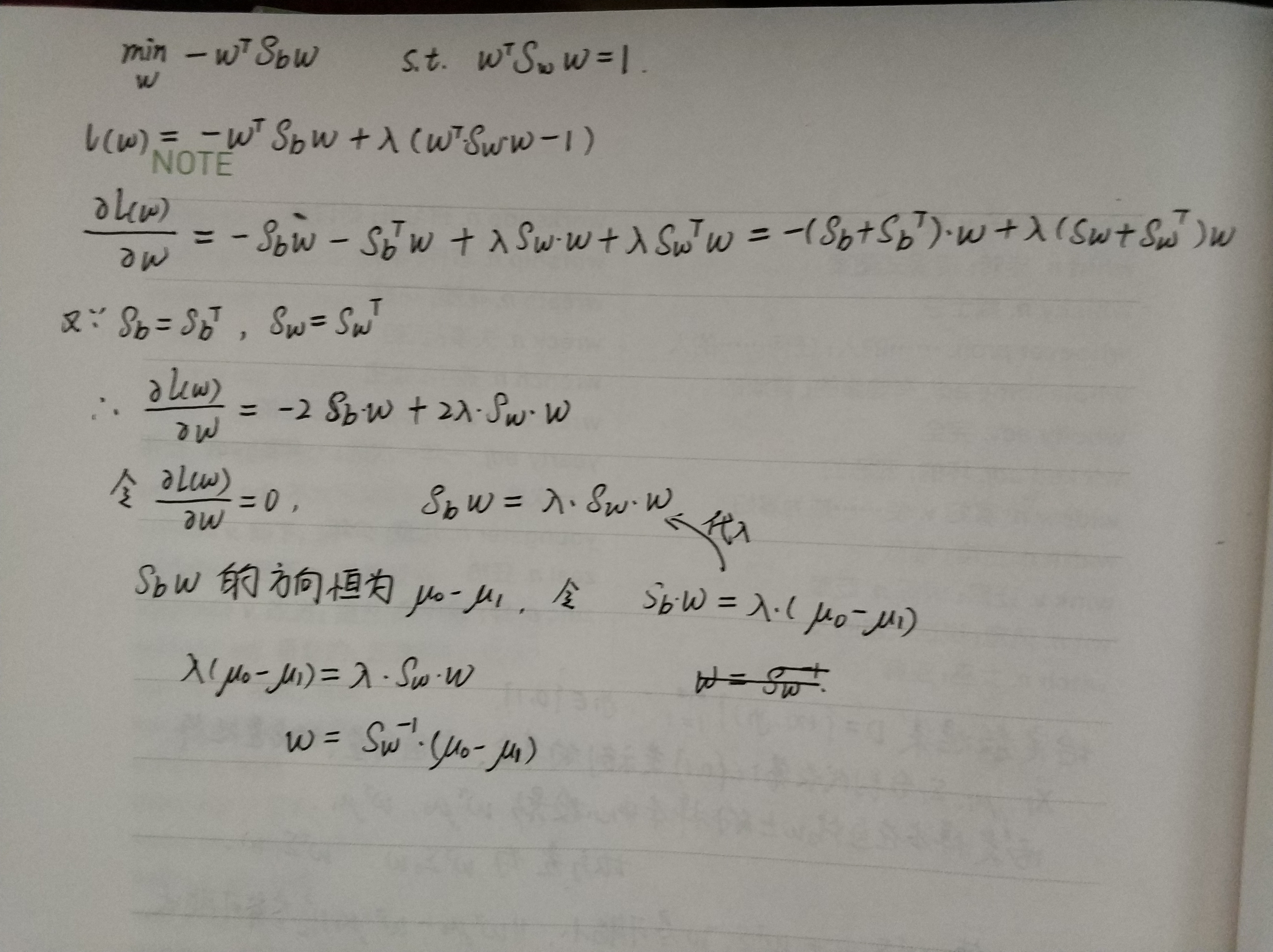
考虑到熟知的稳定性,在实践中通常是对$S_w$进行奇异值分解,即$S_w = U \Sigma V^T$,这里$\Sigma$是一个是对角矩阵,其对角线上的元素是$S_w$的奇异值,然后再由$S_w^{-1} = V \Sigma^{-1} U^T$得到$S_w^{-1}$.
将LDA推广到分类任务:

多分类LDA可以有多种实现方法:使用$S_b, S_w, S_t$三者中的任何两个即可,常用的一种是:

若将$W$视为一个投影矩阵,则多分类LDA将样本投影到$N - 1$维空间,$N - 1$通常远小于数据原有的属性数,可通过这个投影来减少样本点的维数,且投影过程中使用了类别信息,因此LDA也常被视为一种经典的监督降维.
分类学习的拆分策略
不失一般性,考虑N个类别的多分类任务的基本思路是拆解法 将分类问题拆为若干个而分类问题求解
- 一对一 OvO
- 一对其余 OvR
- 多对多 MvM 纠错输出码(ECOC)
如何处理类别不平衡问题
类别不平衡学习的一个基本策略–再缩放
假设训练集是真是样本总体的五篇采样,因此观测几率就代表了真实几率.
若$\frac{y}{1 - y} > \frac{m^+}{m^-}$则,预测为正列.
\[\frac{y'}{1 - y'} = \frac{y}{1 - y} * \frac{m^-}{m^+}\]假设往往不成立,未必能有效地基于训练集观测几率来推断真实几率,现有技术上有三种做法:
- 欠采样 去除一些反例使得正例反例数目相接近 可能会丢失重要信息 EasyEnsemble利用集成学习机制将反例划分成若干个集合共不同学习器使用,对每个学习器进行欠采样却不会丢失重要信息
- 过采样 SMOTE
- 阈值移动
再缩放是代价敏感学习的基础
课后习题
//待补充
Til next time,
gentlesnow
at 16:54
