
【论文研读】 007 LAS
作者:
William Chan Carnegie Mellon University williamchan@cmu.edu
Navdeep Jaitly, Quoc V. Le, Oriol Vinyals Google Brain {ndjaitly,qvl,vinyals}@google.com
论文动机
这是一篇2015年的论文。
深度学习对语音识别产生了很大的影响,改进了语音识别的各个组件。 人们通常用混合DNN+HMM的声学模型来进行语音识别。 DNN对从单词到音速序列的映射模型中产生了显著的效果。 在语言模型中,从n个候选者中进行选择能显著提高识别的准确度。
通常这两个部分是分开训练,而LAS实现端到端的训练来“纠正”这种不相交训练问题。 模型基于CTC和Seq2Seq+Attention。
深度学习模型在序列对应1个标签的情况下表现很好,但在序列对应序列的情况下需要借助HMM和CRF。 这样做的缺点是无法端到端的训练,而且对数据的概率分布提出了假设。
模型解决的问题
与之前方法不同,LAS不会对标记序列做独立性假设,也不依赖HMM。
模型通过Attention提取信息来显著降低时间步的数目。
很少出现的词和未知词(OOV)都可以被Speeller解决, 由于Spelller产生一个词一个词的输出。
而且模型可以很好的处理重复的词。
模型结构
模型由两部分组成:Listener 和 Speller(+Attention)
这两部分同时训练。
模型的各个部分都是非常必要的。 没有Attention机制,模型在大量训练中过度专注于训练结果,而忽视了声学部分的训练。 没有金字塔醒的结构,整个模型训练会非常慢,甚至超过一个月。错误率也会显著提高。 在训练中的一个trick可以降低Speller的过拟合。
整个模型 输入序列为X,输出为y,整个模型目的为: \(P(y\|X) = \prod_i{P(y_i\|X, y_{<i})}\) Listener将输入X转换为低维的序列h,再由h和之前的y进行预测,从Attention选择的候选者中预测最终的y \(h = Listen(x)\) \(P(y\|x) = AttendAndSpell(h, y)\)
整个模型结构如下:
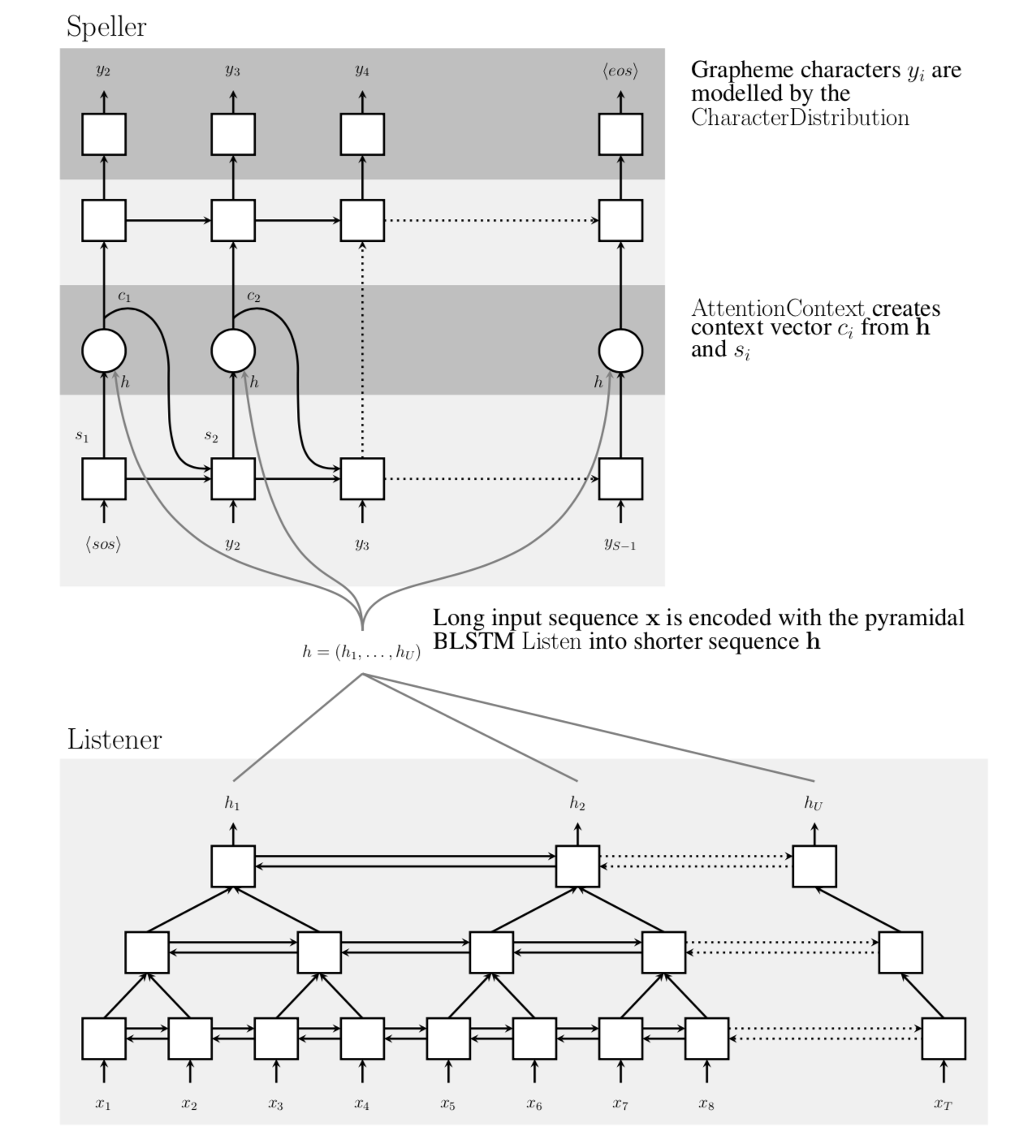
Listener部分:
直接使用BLSTM会使训练Listen很慢,而pBLSTM堆叠起来能显著降低训练时间。 同时也会降低模型复杂度。
Attention+Speller部分:
这部分由Attention+LSTM组成。
在每个输出步,模型产生通过先前产生的字符生成这个字符的概率分布。 y由编码器结果s和上下文c共同决定。 上下文向量由Attention机制产生。 s由先前s_i, y_i, c_i产生。 \(c_i = AttentionContext(s_i, h)\) \(s_i = RNN(s_{i-1}, y_{i-1}, c_{i-1})\) \(P(y_i\|X, y_{<1}) = CharacterDistribution(s_i, c_i)\)
CharacterDistribution是softmax输出的全联接网络,RNN是两层的LSTM。
在每个时间步骤,AttentionContext生成上下文向量, ci将信息封装在生成下一个字符所需的声学信号中。
在每个解码器时间步长i, AttentionContext函数使用向量hu∈h和si计算每个时间步长u的标量能量ei,u。 使用softmax函数将标量能量ei,u转换为经过时间步长(或注意)αi的概率分布。 \(e_{i,u} = <φ (s_i), ψ(h_u)>\) \(\alpha_(i, u) = \frac{exp(e_{i,u})}{\sum_u{exp(e_{i,u})}}\) \(c_i = \sum_u{\alpha_{i,u}h_u}\)
其中φ和ψ是MLP网络。 在收敛时,αi分布通常非常尖锐,并且仅聚焦于几帧h; ci可以看作是h的连续加权特征。
在模型训练过程中,很容易出现错误预测会影响后续预测的情况。 在训练过程中,我们有时会从我们之前的字符分布中抽样,并将其用作下一步预测中的输入, 而不是总是为下一步预测提供真实的目标序列。
随着整个模型变的非常深,预训练变的非常重要。 然而作者发现并不需要预训练。 尝试使用从传统GMM-HMM系统生成的上下文无关或依赖于上下文的音素来预跟踪Listen函数。 softmax网络连接到收听者的输出单元hu∈h,用于制作多帧音素状态预测[34],但没有改进。 还尝试将音素用作共同目标,但未发现任何改进。
在推理阶段,模型需要从近似的值中找到最有可能的值。 \(\hat(y) = argmax_y log{P(y\|x)}\)
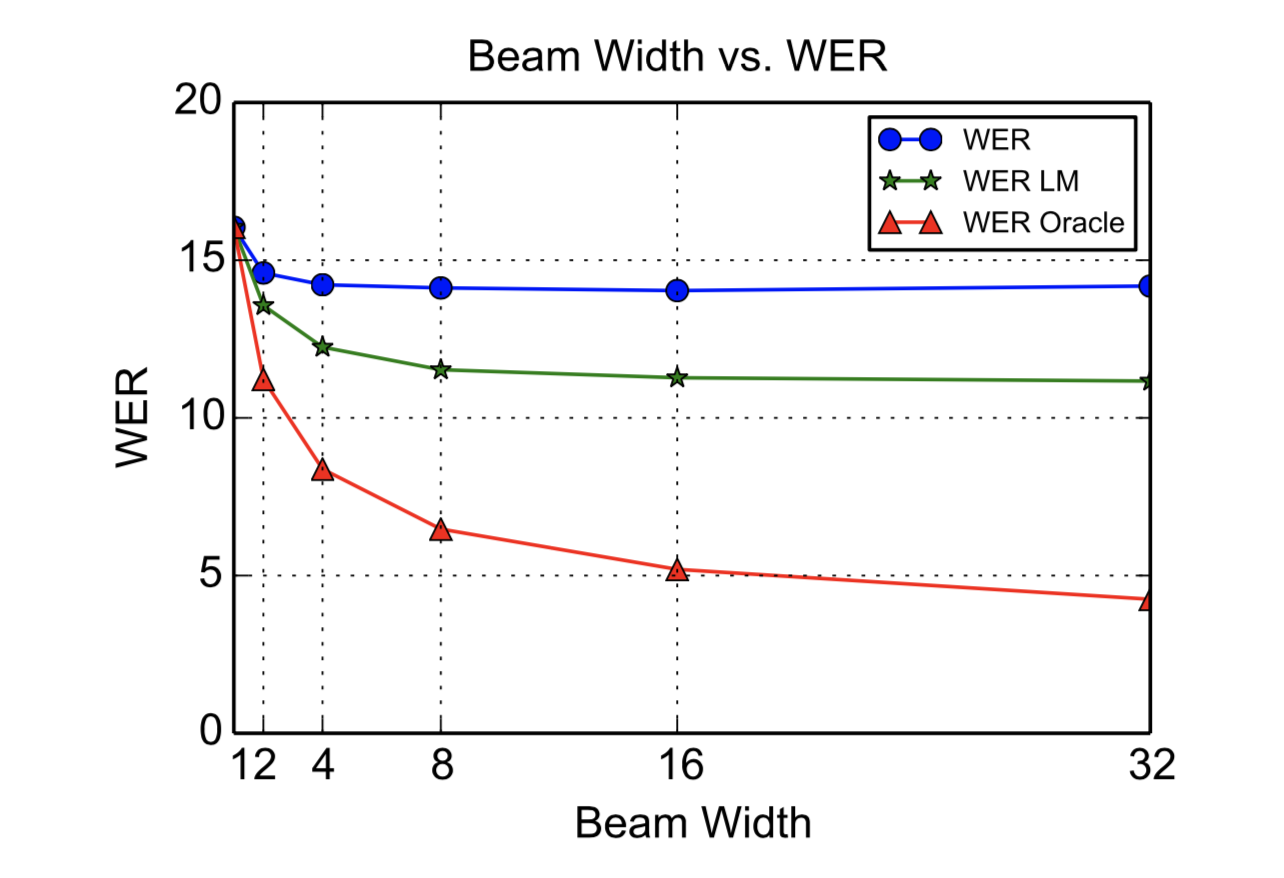
使用简单的从左到右光束搜索算法执行解码。 我们保留一组β部分假设,从句子开头⟨sos⟩标记开始。 在每个时间步长,beam中的每个部分假设随着每个可能的特征扩展,并且仅保留β最可能的beam。 当遇到⟨eos⟩令牌时,它将从beam中移除并添加到结果集中。
可以选择添加字典以将搜索空间约束为有效单词,但是我们发现这不是必需的,因为模型几乎一直学会拼写真实单词。
我们可以使用与传统语音系统类似的文本语料库训练的语言模型
模型对于端文本存在小的偏差。 我们通过假设中的字符数$|y|_c$对概率进行归一化,并将其与语言模型概率PLM(y)相结合: \(s(y\|x) = \frac{log P(y\|x)}{\|y\|\_c} + λlog P_{LM}{(y)}\) λ是我们的语言模型权重,可以通过验证集来确定。
模型结果
通过这些改进,LAS在Google语音搜索任务的子集上实现了14.1%的WER,没有字典或语言模型。 当与语言模型重新结合时,LAS达到10.3%的WER。 相比之下,Google最先进的CLDNN-HMM系统在同一数据集上实现了8.0%的WER。
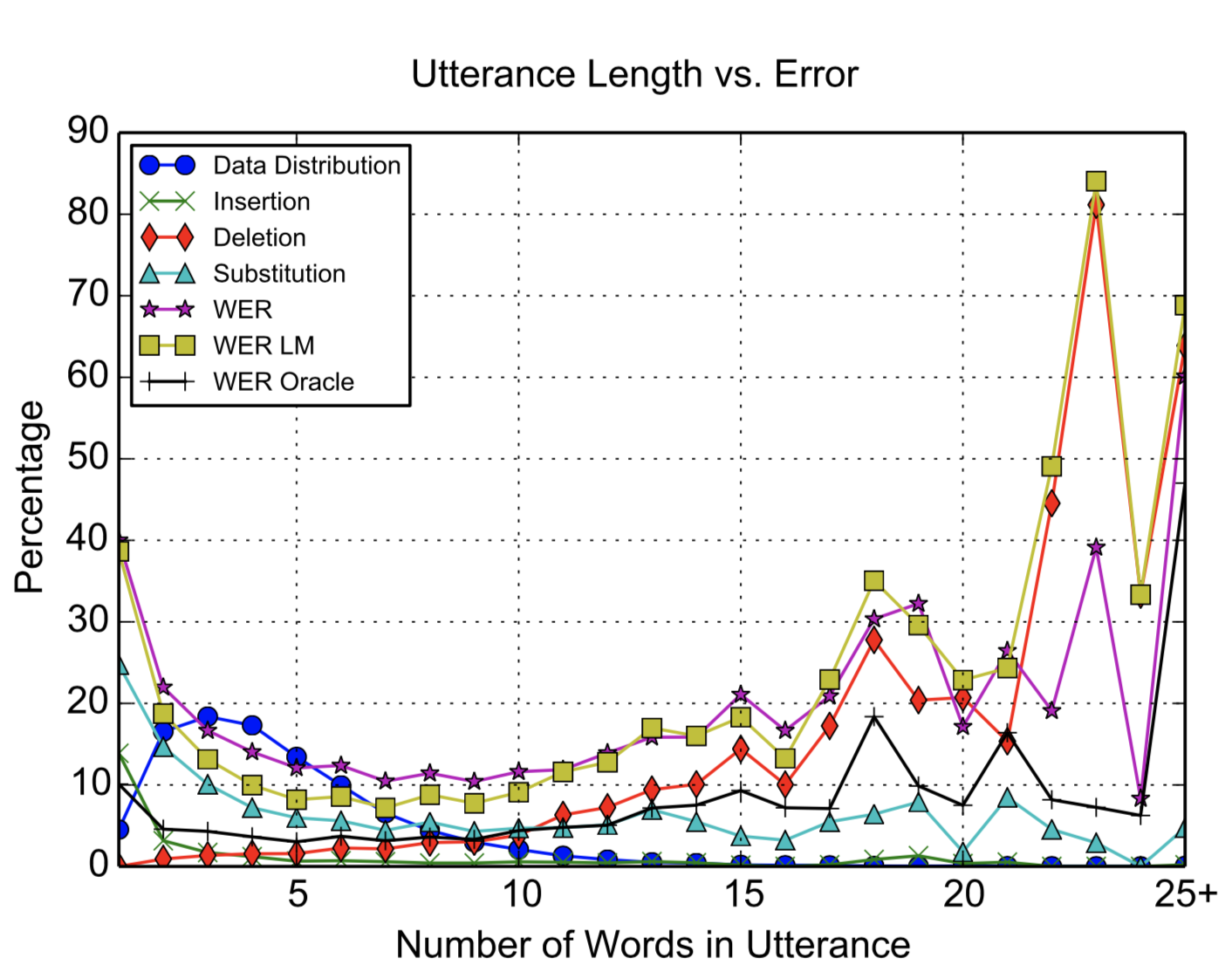
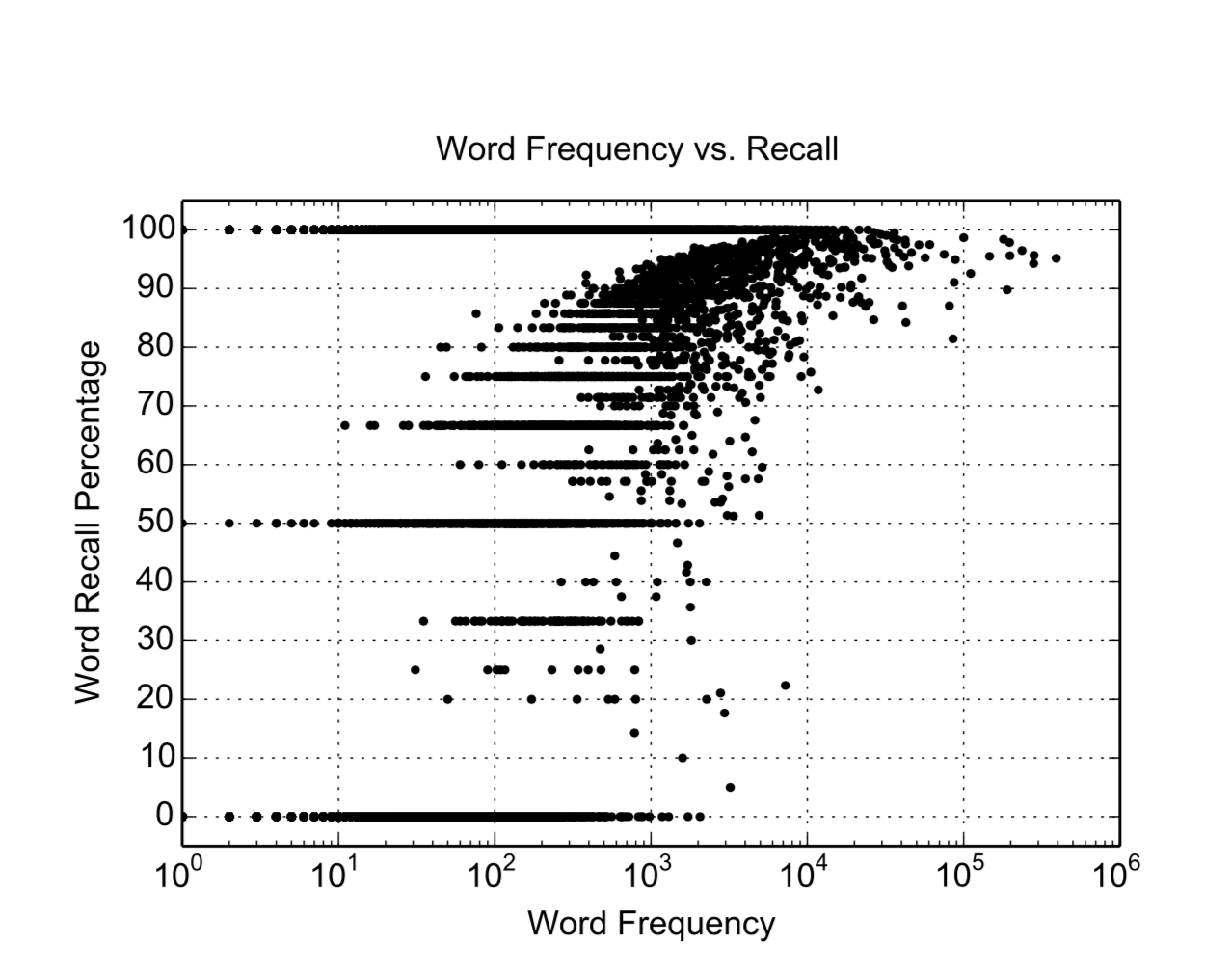
超参数对于模型的影响


模型改进方向
我们怀疑卷积滤波器可以改善结果,因为据报道,与非卷积架构相比,干净语音相对WER提高了5%,噪声语音提高了7%。
Til next time,
gentlesnow
at 18:13
