
【论文研读】 008 A Survey on Dialogue Systems
2017年的一篇论文
对话系统的调查
概述
深度学习通过利用大连的数据来学习特征表示和回应的生成策略,只需要少量的人工。
现有对话系统分为任务型和非任务型对话系统。
这篇论文首先对话系统最新的研究进展和可能的研究方向,然后说明深度学习技术代表算法,最后探讨了可能将对话系统引入一个新的阶段的研究。
介绍
对话系统取得进展的原因
- 大量的数据、文献的出现
- 深度学习技术在捕获大量数据的复杂模式被证明是有效的,在CV、NLP和推荐系统中得到应用。
任务型对话系统:
任务型对话系统的广泛做法是建立一个管道模型:
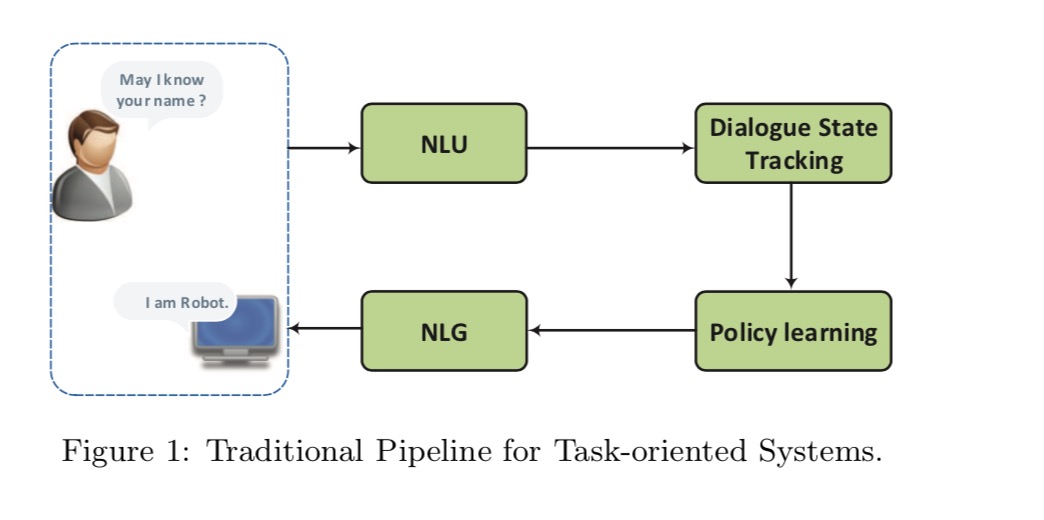 系统首先理解人类给出的信息,将其表达为内部的状态。根据对话状态采取行动,最后将对话表示为自然语言的形式。尽管语言理解是通过统计模型处理的,但大多数部署的对话系统仍然使用手动功能或手工制作的规则来进行状态和动作空间表示,意图检测和插槽填充。这不仅使部署真实对话系统变得昂贵而耗时,而且还限制了其在其他领域的使用。
系统首先理解人类给出的信息,将其表达为内部的状态。根据对话状态采取行动,最后将对话表示为自然语言的形式。尽管语言理解是通过统计模型处理的,但大多数部署的对话系统仍然使用手动功能或手工制作的规则来进行状态和动作空间表示,意图检测和插槽填充。这不仅使部署真实对话系统变得昂贵而耗时,而且还限制了其在其他领域的使用。
许多基于深度学习的算法通过以高维分布式方式学习特征表示来缓解这些问题,并在这些方面取得显着改进。
此外深度学习还尝试构建端到端的面向任务的对话系统,有助于实现对于特定语料库之外的语料库进行对话。
非任务型对话系统:
非任务型对话系统可以在开方域上执行闲聊,但在真正应用时也是具体到特定的领域中。
非任务型对话系统有两种方法
- 生成方法 例如Seq2Seq模型
- 基于检索的方法 从对话库中找到当前对话的响应
任务型对话系统
管道模型
管道模型由4个部分组成
- 自然语言理解 将用户语言解析为预定义的语义槽
- 对话状态跟踪 管理每个回合的输入以及对话历史并输出当前对话状态。
- 对话规则学习 基于当前对话状态学习下一个动作
- 自然语言生成 将选定的操作映射到其表面并生成响应。
自然语言理解
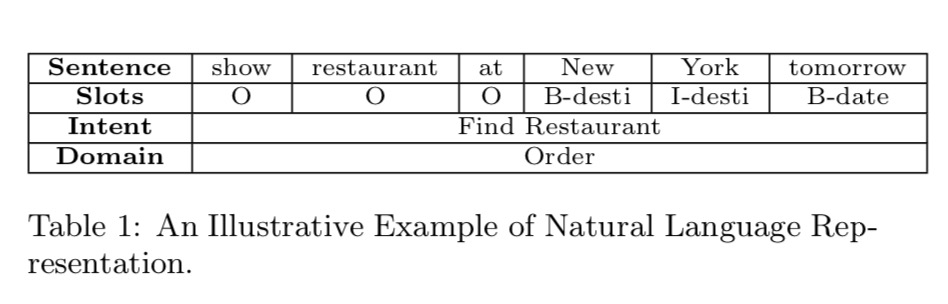
给定一个话语,自然语言理解将其映射到语义槽。根据不同的场景预先定义插槽。上表表示出了自然语言表示的示例,其中“New York”是指定为地址的槽值,并且还分别指定了域和意图。通常,有两种类型的表示。一个是话语等级的类别,例如用户的意图和话语的类别。另一种是单词级信息提取,例如命名实体识别(NER)和插槽填充(slot filling)。
通过分类器将用户话语分类为预定于的意图之一。一般采用CNN提取Query向量表示的特征作为分类的特征。在类别和域分类也使用类似的方法。
slot filling插槽填充是口语理解的另一个挑战性问题。 与意图检测不同,插槽填充通常被定义为序列标记问题,其中句子中的单词被赋予语义标签。 输入句子序列输出solt/concept id序列。
在这一方面,深度信念网络与CRF有相当大的提升。
对话状态跟踪
传统的结构被称为槽填充或者语义框架。传统的方法采用手工制定的规则来选择可能的结果,然而这些基于规则的系统容易发生频繁的错误,得不到期望的结果。
统计对话系统在面对负载的情况时,通常保持对真实状态的多个假设。 在对话状态跟踪挑战赛中,基于统计的方法包括:手工规则、CRF、最大熵模型、网络式排名。
深度学习中的信念跟踪belif tracking被引入,它使用滑动窗口在任意数量的可能值上输出一系列概率分布。而且不受训练域的限制。目前的做法有multi-domain RNN dialog state tracking models,它首先使用所有可用数据来训练非常一般的信念跟踪模型,然后专门针对每个域的一般模型来学习特定于域的行为;neural belief tracker (NBT)。
对话规则学习
以对话状态跟踪的状态表示为条件,对话规则学习是生成下一个可用的系统动作。
通常采用基于规则的学习来预热系统,随后对规则学习中的动作进行监督学习。深层强化学习在这一方面由于完全随机、基于规则、基于统计的baseline模型。
自然语言生成
一个好的生成器的评价指标:
- adequacy, 充分性
- fluency, 流畅性
- readability, 可读性
- variation, 多变性
基于LSTM的方法将对话行为和slot-value对转换成one-hot控制向量作为附加输入。
也有采用前向RNN生成器和一个CNN重排列器以及反向RNN重排列器。所有子模块被联合优化生成回复。
为了解决重复和省略问题可以使用一个额外控制单元来控制对话行为。 拓展这一方法可以使用对话性温门控制LSTM的输入向量。
也有采用LSTM为基础的Seq2Seq结构来处理问句信息,情感语义槽和对话行文控制来生成答句。 它使用注意机制来处理以解码器的当前解码状态为条件的关键信息。 神经网络的模型将对话行为作为编码嵌入,根据不同行为生成变体答案。
也有采用Seq2Seq的自然语言生成模型加入对话行为的深层语法依赖树,将回答进行拓展,使之能够适用于用户的说话方式生成基于上下文的回应。
端到端模型
任务型对话系统传统管道模型有两个问题:
- credit assignment problem 信用分配问题 最终用户的反馈很难反馈到前面的组件中
- process interdependence 过程依赖 一个组件的输入依赖于另一个的输出,将一个组件调整为新环境需要将其他组件也做调整完成全局优化。
基于端到端的任务型对话系统将对话系统是为学习从对话历史到系统回应response的问题,采用Seq1Seq模型。然而这一模型需要大量的训练数据,而且缺少对对话系统的控制没有稳健的策略。
端到端的强化学习的方法,在对话管理模块联合训练对话状态跟踪和对话策略学习。 在对话中,代理向用户询问一系列是/否问题以找到正确答案。 当应用于猜测着名人物用户所想到的面向任务的对话问题时,这种方法被证明是有希望的。
面向任务型对话系统通常需要查询数据库。先前的系统通过向知识库发出符号查询以基于其属性检索条目来实现这一点,其中执行对输入的语义解析以构造表示代理关于用户目标的信念的符号查询。
这种方法有两种缺点:
- 检索结果不包含任何有关语义分析中不确定性的信息
- 检索操作是不可微分的,因此解析器和对话策略是分开训练的。这使得在部署系统后,用户反馈的在线端到端学习变得困难。
有人扩展了现有的循环网络体系结构,在知识库的基础上采用了基于注意力的可区分键值检索机制,这种机制受到键值记忆网络的启发。 也用知识库中的诱导“soft”后验分布代替符号查询,指示用户感兴趣的实体。将软检索过程与强化学习者相结合。
非任务型对话系统
非任务型对话系统专注于开放领域的聊天。
一般来说,聊天机器人可以通过生成方法或基于检索的方法来实现。 生成模型能够生成更多适当的响应,这些响应可能从未出现在语料库中,而基于检索的模型享有信息和流畅响应的优势,因为它们从存储库中为当前会话选择了适当的响应 使用响应选择算法。
生成模型
最初提出了一种生成概率模型,它基于基于短语的统计机器翻用于模拟微博上的对话。它将响应生成问题视为翻译问题。但是,发现生成回复比在语言之间进行转换要困难得多。这很可能是由于广泛的合理回复和帖子与答复之间缺乏短语对齐。在机器翻译中应用深度学习的成功,即神经机器翻译,激发了神经生成对话系统研究的热情。
Seq2Seq模型
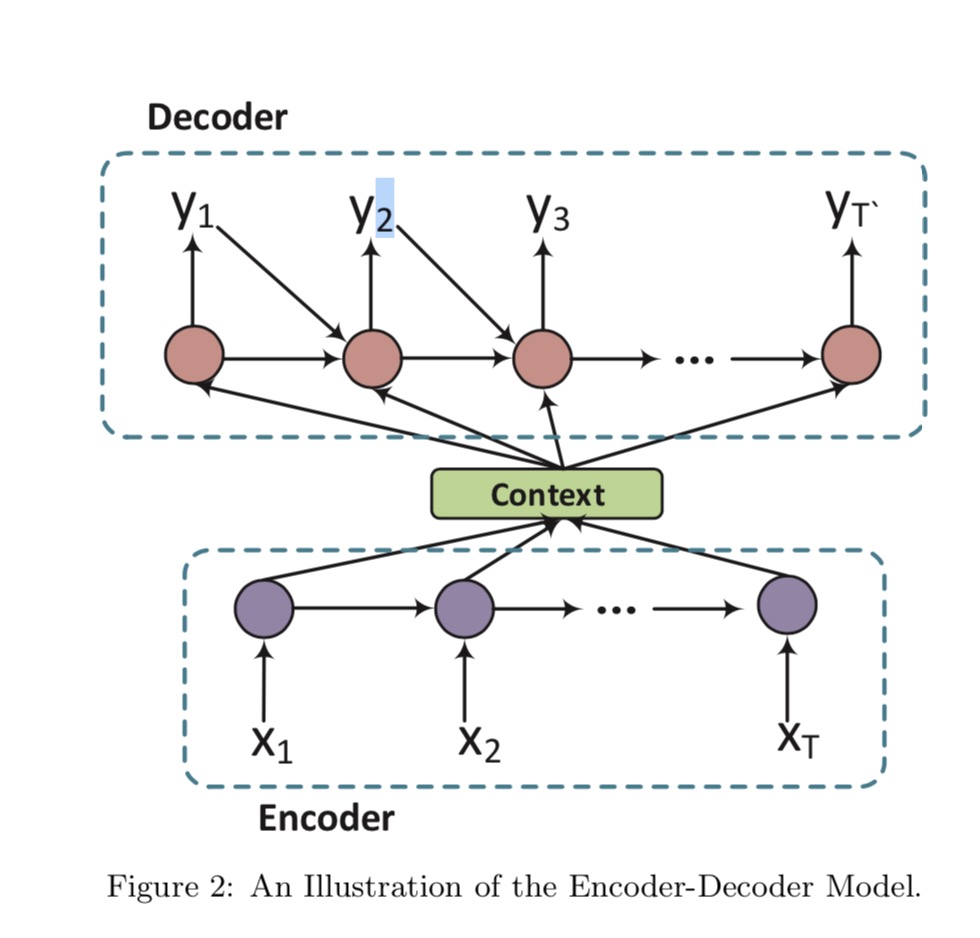
Message: $X=(x_1, x_2, …, x_T)$ Response: $Y=(y_1, y_2, …, y_{T^`})$ model: 最大化Y在X条件下生成的可能 $P(y_1, y_2, …, y_{T^`}|x_1, x_2, …, x_T)$
\(h_t =f(x_t,h_{t−1})\) \(s_t =f(y_{t−1},s_{t−1},c)\) \(p_t = softmax(s_t,y_{t−1})\)
$c$是与最后一个单词$h_t$对应的隐藏状态。
Seq2Seq: \(P(y_1, y_2, ..., t_{T^\`}\|x_1, x_2, ..., x_T)=P(y_1\|c)\ti_{t=2}^{T\`}{P(y_{T^\`}|c, y_1, y_2, ..., y_{t-1})}\)
然后通过注意机制改善了性能,其中Y中的每个单词以不同的上下文向量c为条件,观察到Y中的每个单词可能与x中的不同部分相关。 特别地,yi对应于上下文向量ci,ci是编码器隐藏状态h1,…,hT的加权平均值: \(c_i =\sum^T_{j=1}{\alpha_{ij} h_j}\) $\alpha_{ij}$由以下计算得到: \(\alpha = \frac{exp(e_{ij})}{\sum_{k=1}^{T}{exp(e_{ik})}}\) \(e_{ij} = g(s_{t-1}, h_j)\) g式多层感知机。
这些模型能够利用大量数据来学习有意义的自然语言表示和生成策略,同时需要最少量的领域知识和手工制作。
Dialogue Context
考虑先前话语的能力是构建可以保持对话活跃和吸引人的对话系统的关键。
通过连续表示或嵌入单词和短语来表示整个对话历史(包括当前消息),解决了上下文敏感响应生成的挑战。使用注意力机制拓展hierarchical models捕获个别话语的含义。 层次RNN通常优于非层次RNN,对于上下文信息,神经网络倾向于产生更长,更有意义和更多样的回复。
Response Diversity
当前序列到序列对话系统中的一个具有挑战性的问题是,它们倾向于产生琐碎或不明确的,普遍相关的响应,几乎没有意义,这通常涉及高频率短语。
这种行为可归因于通用响应的相对较高的出现频率。 缓解这种挑战的一种有希望的方法是找到更好的目标函数。
可以在神经模型在优化给定输入的输出的可能性时给予“安全响应”的高概率。 他们使用了在语音识别中首次引入的最大互信息(MMI)作为优化目标。 它测量了输入和输出之间的相互依赖性,虑了响应对消息的逆相关性。 也可以将逆文档频率(IDF)纳入训练过程以测量响应多样性。
一些研究意识到解码过程是冗余候选响应的另一个来源。 使用逐点互信息(PMI)来将名词预测为关键词,反映回复的主要要点,然后生成包含给定关键词的回复。 另一系列工作的重点是通过引入随机隐变量来产生更多样化的产出。他们证明自然对话不是决定性的 - 对同一信息的回复可能因人而异。
Topic and Personality
明确学习对话的固有属性是改善对话多样性和确保一致性的另一种方法。
人们经常将他们的对话与局部相关的概念联系起来,并根据这些概念创建他们的回答。使用Twitter LDA模型获取输入主题,将主题信息和输入表示提供给联合注意模块,并生成与主题相关的响应。
将情感嵌入到生成模型中,并在困惑中取得了良好的表现。
为系统提供了一个配置文件的身份,以便系统可以一致地回答个性化问题。
由于训练数据来自不同的不同发言者,提出了一种两阶段训练方法,该方法使用大规模数据初始化模型,然后微调模型以产生个性化响应。 使用转移强化学习来消除不一致。
Outside Knowledge Base
人类对话与对话系统的一个重要区别在于它是否与现实相结合。合并外部知识库(KB)是一种很有前途的方法,可以弥合对话系统与人类之间的背景知识差距。
Memory network是一种处理具有知识库的问题回答任务的经典方法。因此,将它应用于对话生成是非常简单的。 通过将CNN嵌入和RNN嵌入到多模式空间中并在困惑中取得进展,开展了具有背景知识的开放域对话。
与知识库中元组检索的一般方法不同,有人使用知识库中的单词与生成过程中的常用单词。研究表明,所提出的模型能够通过参考知识库中的事实来产生对问题的正确答案。
Interactive Dialogue learning
通过互动学习是对话系统的最终目标之一。
为了进一步尝试提高机器人从交互中学习的能力。通过对文本和数字反馈使用策略学习和前向预测,模型可以通过(半)在线方式与人交互来改善自身。
Evaluation
面向任务的对话系统可以基于人工生成的监督信号进行评估,对非面向任务的对话系统产生的响应的质量进行自动评估仍然是一个悬而未决的问题。
目前广泛应用的方法:
- BLEU
- METEOR
- ROUGE
基于检索的方法
基于检索的方法的关键是消息响应匹配。 匹配算法必须克服消息和响应之间的语义差距
Single-turn Response Matching
基于检索的算法早期广泛应用于单轮对话中。
通常将上下文与候选回应分别编码为向量,然后计算两个向量的匹配分数。
通过利用深度卷积神经网络架构来学习消息和响应的表示,或者直接学习两个参数的交互表示,然后用多层感知器来计算匹配分数,从而改进了模型。
提取了依赖树匹配模式,并将它们用作深度前馈神经网络的稀疏独热输入,用于上下文响应匹配。
将Twitter LDA模型生成的主题向量合并到基于CNN的结构中,以增强具有丰富内容的响应。
Multi-turn Response Matching
在多轮回复选择中,将当前消息和先前的话语作为输入。该模型选择一个与整个上下文相关的响应。 重要的是在先前的话语中识别重要信息并正确地模拟话语关系以确保对话的一致性。
通过基于RNN / LSTM的结构将上下文(所有先前话语和当前消息的串联)和候选响应编码成上下文向量和回复向量,然后基于这些结果计算匹配度分数。
通过卷积神经网络在多个粒度级别的上下文中将响应与每个话语相匹配,进一步改善了对话和上下文信息的利用,然后通过递归神经网络按时间顺序累积向量 模仿话语之间的关系。
混合的方法
基于检索的系统通常会提供精确但直率的答案,而基于生成的系统往往会提供流畅但毫无意义的响应。 在混合模型中,将检索到的候选回复与原始消息一起送到基于RNN的响应生成器。通过再排序得到最有可能的回复。
总结
深度学习已成为对话系统的基本技术。研究人员研究将神经网络应用于传统的面向任务的对话系统的不同组成部分,包括自然语言理解,自然语言生成,对话状态跟踪。近年来,端到端框架不仅在非任务导向的聊天对话系统中受到欢迎,而且在以任务为导向的对话系统中也变得流行。深度学习能够利用大量数据,并有望建立一个统一的智能对话系统。它模糊了面向任务的对话系统和非任务导向系统之间的界限。特别是,聊天对话系统由Seq2Seq模型直接建模。随着强化学习表示了状态行动空间整合了整个管道模型,任务型的对话系统也开始朝着端到端的方向发展。
端到端的模型还有很多缺点。以下是可能的研究方向
- Swift Warm-Up 快速预热 尽管端到端模型已经吸引了最近研究的大部分注意力,但我们仍然需要在实际对话工程中依赖传统的管道,特别是在新的领域预热阶段。 每日会话数据非常“大”,但是,特定域的对话数据非常有限。 特别是,领域特定的对话数据收集和对话系统构建是劳动的。 基于神经网络的模型可以更好地利用大量数据。 我们需要新的方式来弥合热身阶段。 对话代理人有能力通过与人的互动来学习。
- Deep Understanding 当前基于神经网络的对话系统严重依赖于大量不同类型的注释数据,以及结构化知识库和会话数据。 他们学会说话,一次又一次地模仿一种反应,就像婴儿一样,反应仍然缺乏多样性,有时没有意义。 因此,对话代理应该能够通过对语言和现实世界的深刻理解来更有效地学习。 具体而言,如果对话代理可以从人类指令中学习以摆脱反复训练,那么它仍然具有很大的潜力。 由于互联网上有大量的知识,如果能够利用这种非结构化知识资源来理解,对话代理可以更聪明。 最后但同样重要的是,对话代理应该能够做出合理的推理,找到新的东西,分享跨域的知识,而不是重复像鹦鹉这样的词。
- 隐私保护。 广泛应用的对话系统服务于大量人群。 我们必须注意到我们正在使用相同的对话助手这一事实。 通过互动,理解和推理的学习能力,对话助理可以无意中和隐含地存储一些敏感信息。 因此,在构建更好的对话系统的同时保护用户的隐私非常重要。
Til next time,
gentlesnow
at 20:00
