
【论文研读】 009 Denoising Distantly Supervised Open-Domain Question Answering
2018年的一篇论文
对远程监督学习开放域问答(Distantly Supervised Open-Domain Question Answering,DS-QA)进行去噪。
代码地址: https: //github.com/thunlp/OpenQA
论文动机
DS-QA试图从无标签文本中找到问答系统的答案。
现有的DS-QA模型通常从大规模语料库中检索相关段落,并应用阅读理解技术从最相关的段落中提取答案。 他们忽略了其他段落中包含的丰富信息。 此外,远程监管数据不可避免地伴随着错误的标签问题,并且这些噪声数据将大大降低DS-QA的性能。
许多阅读理解系统能够取得好的结果主要归因于他们采用了多层的结构和注意力机制。
尽管取得了一定的成功,但是现有的阅读理解模型依赖于预先定义的相关文本,无法处理真实世界的情况。因此无法满足开放域的QA任务。
近年来,研究人员试图用大规模的未标记的问题回答开放域问题。 Chen在2017年提出了一个远程监控的开放域问答(DS-QA)系统,该系统使用信息检索技术从维基百科中获取相关文本,然后应用阅读理解技术来提取答案。
DS-QA是一个自动收集相关文本的过程,不可避免要处理噪音: 例如: question: “Which country’s capital is Dublin?”
- “Dublin is the largest city of Ireland …” 这一段没有直接回答问题
- ‘Dublin is the capital of Ireland. Besides, Dublin is one of the famous tourist cities in Ireland and …” 第二个“Dublin”不是答案的正确token
为了解决这个问题,Choi在2017年将DS-QA中的答案生成分为两个模块,包括在文档中选择目标段落,并通过阅读理解从目标段落中提取正确答案。 此外,Wang在2018年使用强化学习来共同训练目标段落选择和答案。
这些方法只根据最相关的段落提取答案,这将丢失段落中包含的大量丰富信息。 事实上,正确的答案经常在多个段落中提及,问题的不同方面可能会在几个段落中提到。 因此,Wang在2018年建议进一步明确地从不同段落中收集证据以重新排列提取的答案。 然而,重新排序的方法仍然依赖于现有DS-QA系统所获得的答案,并且未能大大解决DS-QA的噪声问题。
模型贡献
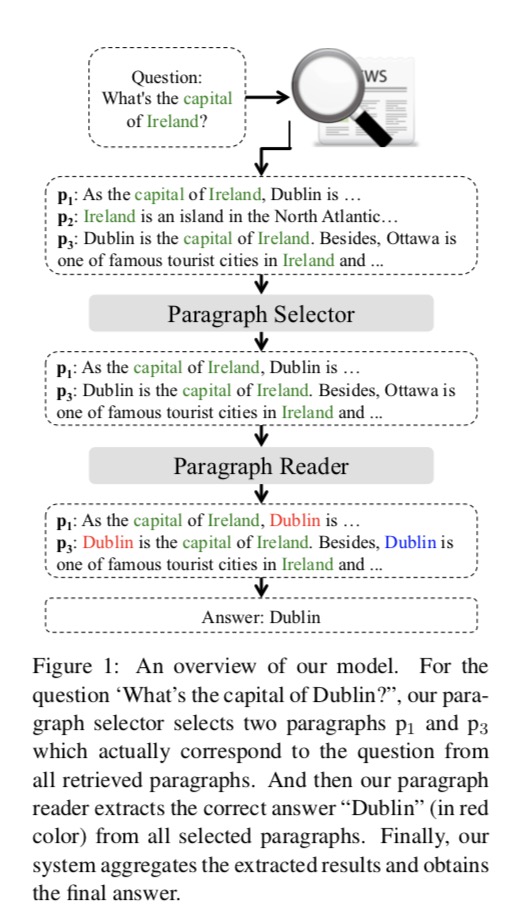 如上图所示,为了解决这些问题,论文提出了一种针对DS-QA的粗到细去噪模型。
如上图所示,为了解决这些问题,论文提出了一种针对DS-QA的粗到细去噪模型。
该模型使用段落选择器来过滤掉那些嘈杂的段落,并使用段落阅读器从那些去噪的段落中提取正确的答案。
模型首先通过信息检索从大规模语料库中检索段落。 在此之后,为了利用所有信息段落,作者采用快速段落选择器来浏览所有检索到的段落并过滤掉那些嘈杂的段落。 然后作者应用一个精确的段落阅读器来仔细阅读每个选定的段落以提取答案。 最后,作者汇总所有选定段落的派生结果,以获得最终答案。 段落选择器的快速浏览和作者的方法中的段落阅读器的密集阅读使得DS-QA能够对噪声段落进行去噪以及保持效率。
模型结构
问题序列: $q = (q^1, q^2, …, q^{|q|})$ 查找到的m个段落: $P = {p_1, p_2, …, p_m}$ 每个段落: $p_i = (p_i^1, p_t^2, …, p_i^{|p_i|})$ 模型的目的是度量问题q的答案在相关段落p的概率。
整个模型分为两个部分
-
Paragraph Selector 段落选择器 度量所有相关段落的概率分布$P(p_i q, P)$ -
Paragraph Reader 段落阅读器 给定问题$q$和段落$p_i$,计算出通过多层LSTM提取出的答案的概率$P(a q, p_i)$
段落选择器
段落编码:
首先将段落$p_i$中的每个单词$p_i^j$表示为单词向量$p_i^j$,然后将每个单词向量馈送到神经网络中以获得隐藏表示$\hat{p}_i^j$。 在这里,我们采用两种类型的神经网络,包括:
- MLP $\hat{p}_i^j = MLP(p_i^j)$
-
RNN ${\hat{p}_i^1, \hat{p}_i^2, …, \hat{p}_i^{ p_i }} = LSTM({p_i^1, p_i^2, …, p_i^{ p_i }})$
问题编码:
同段落编码相似。
- MLP $\hat{q}_i^j = MLP(q_i^j)$
-
RNN ${\hat{q}_i^1, \hat{q}_i^2, …, \hat{q}_i^{ q }} = LSTM({q_i^1, q_i^2, …, q_i^{ q }})$
通过自注意力机制获得问题的最终的问题表示: \(\hat{q} = \sum_j{\alpha^j \hat{q}^j}\) $\alpha^j$表示每个问题单词的重要性: \(\alpha^i = \frac{exp(w_b q_i)}{\sum_j{exp(w_b q_j)}}\) $w$是个学到的权重向量。
通过max-pooling层和softmax层计算每个段落的概率: \(P(p_i\|q, P) = softmax(\max_j(\hat{P}_i^j W q))\) $W$是个学到的权重矩阵。
段落阅读器
与段落阅读器类似,我们首先通过多层双向LSTM将每个段落pi编码。 通过自注意多层双向LSTM获得问题的嵌入q̄。
段落阅读器主要用来提取正确答案token的范围。 将其分为预测答案的起始和终止部分。 \(P(a\|q, p_i) = P_s(a_s) P_e(a_e)\) \(P_s(a_s) = softmax(p_i^j W_s q)\) \(P_e(a_e) = softmax(p_i^j W_e q)\) $W_s$和$W_q$是两个学到的权重矩阵。
在DS-QA中,由于我们没有手动标记答案的位置,因此我们可能会在段落中将几个标记与正确的答案相匹配。
${(a_s^1, a_e^1), …, (a_s^{|a|}, a_e^{|a|})}$是标记开始和结束的集合。 这一等式可通过两种方式进一步定义:
-
Max 假设段落中只有一个标记表示正确的答案,最大化所有候选令牌的概率来定义提取答案a的概率:$P(a q, p_i) = \max_j P_s(a_s) P_e(a_e)$ -
Sum 将所有令牌与正确答案相匹配,$P(a q, p_i) = \sum_j P_s(a_s) P_e(a_e)$
训练
使用最大似然估计来定义损失函数L: \(L(\theta) = - \sum_{(\hat{a}, q, P) \in T}{log(P(a\|q, P) - \alpha R(P))}\) θ表示模型的参数,a表示正确答案,T表示整个训练集,R(P)是段落选择器上的正则化项,以避免其过度拟合。
如果段落与答案相关,R(P)被定义为$P(p_i|q, P)$和条件分布X($X = \frac{1}{c_p}$, ${c_p}$是包含正确答案的段落数)之间的KL距离。 \(R(P) = \sum_{p_i \in P}{log(\frac{X_i}{P(p_i\|q, P)})}\) 在测试期间,我们提取答案a的最高概率: \(\hat{a} = \argmax_a{P(a\|q,P)} = \argmax_a \sum_{P_i \in P}{P(a\|q, p_i) P(p_i\|q, P)}\)
模型成绩
包括Quasar-T,SearchQA和TriviaQA在内的真实数据集的实验结果表明,与所有基线方法相比,模型通过汇总所有信息段落的提取答案,实现了显着和持续的改进。 特别是通过选择一些信息段落表明我们的模型可以达到相当的性能,这大大加快了整个DS-QA系统的速度。
模型选择了五个训练数据集
- Quasar-T 由43,000个开放域琐事问题组成,他们的答案是从ClueWeb09数据源中提取的,这些段落是通过从ClueWeb09数据中检索每个问题的50个句子获得的
- SearchQA 是一个大型的开放域名问答数据集
- TriviaQA 包括由琐事爱好者撰写的95,000个问答对,并独立收集证据文件,平均每个问题6个,并利用Bing Web搜索API收集50个与之相关的网页的问题
- CuratedTREC 基于TREC QA任务的基准,其包含从TREC1999,2000,2001和2002的数据集中提取的2,180个问题
- WebQuestions 用于回答自由基知识库中的问题,该知识库是通过Google Suggest API抓取问题而构建的,并且使用英文维基百科检索段落
对比的基线模型有:
- GA 通过门控注意机制对段落执行多跳
- BiDAF 具有双向注意力流动网络的阅读理解模型
- AQA 一个强化学习模型,学习重写问题并汇总重写问题产生的答案
- R^3 一个强化学习模型,利用排名器选择最可能的段落来训练阅读理解模型
训练设置: 在开发集上调整模型,利用网格搜索来确定最佳参数。 LSTM的隐藏大小n∈{32,64,128,…,512}。 给文档和问题编码的LSTM的层数在{1,2,3,4}。 regularization weight正则化权重在 {0.1,0.5,1.0,2.0}。 batch size 批量大小在{4, 8, 16, 32, 64, 128}。 最佳参数分别为:128,3,0.5,32. 对于其他参数,由于它们对结果几乎没有影响,遵循Chen在2017年论文中使用的设置。
Our+FULL模型首先通过使用Our+AVG模型的预训练初始化,并且将所有训练数据的迭代次数设置为10.对于预训练的字嵌入,我们使用300 -dimensional GloVe6词嵌入。
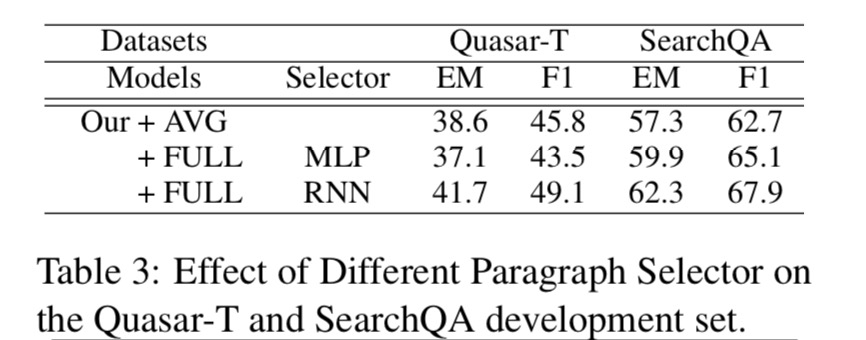 由于我们的模型将不同类型的神经网络(包括MLP和RNN)作为我们的段落选择器,作者研究了不同段落选择器对Quasar-T和SearchQA开发集的影响。
我们的RNN段落选择器可以在Quasar-T和SearchQA上实现统计上显着的改进。 请注意,与Our + AVG相比,使用MLP段落选择器的Our+FULL甚至在Quasar-T数据集上表现更差。 它表明MLP段落选择器不足以区分段落是否回答了问题。 由于RNN段落选择器始终如一地改进了所有评估指标,因此我们在以下实验中将其用作默认段落选择器。
由于我们的模型将不同类型的神经网络(包括MLP和RNN)作为我们的段落选择器,作者研究了不同段落选择器对Quasar-T和SearchQA开发集的影响。
我们的RNN段落选择器可以在Quasar-T和SearchQA上实现统计上显着的改进。 请注意,与Our + AVG相比,使用MLP段落选择器的Our+FULL甚至在Quasar-T数据集上表现更差。 它表明MLP段落选择器不足以区分段落是否回答了问题。 由于RNN段落选择器始终如一地改进了所有评估指标,因此我们在以下实验中将其用作默认段落选择器。
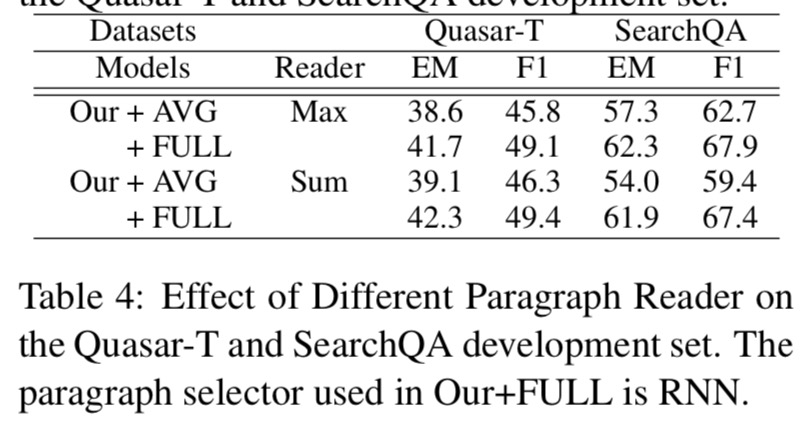 所有具有Sum或Max段落阅读器的模型在大多数情况下都具有相似的性能,但与SearchQA数据集上的Sum阅读器相比,带有Max阅读器的Our + AVG增量约为3%。 它表明Sum读取器更容易受到噪声数据的影响,因为它将与答案匹配的所有令牌视为基本事实。 在下面的实验中,我们选择Max阅读器作为我们的段落阅读器,因为它更稳定。
所有具有Sum或Max段落阅读器的模型在大多数情况下都具有相似的性能,但与SearchQA数据集上的Sum阅读器相比,带有Max阅读器的Our + AVG增量约为3%。 它表明Sum读取器更容易受到噪声数据的影响,因为它将与答案匹配的所有令牌视为基本事实。 在下面的实验中,我们选择Max阅读器作为我们的段落阅读器,因为它更稳定。
模型在五个数据集上的表现:
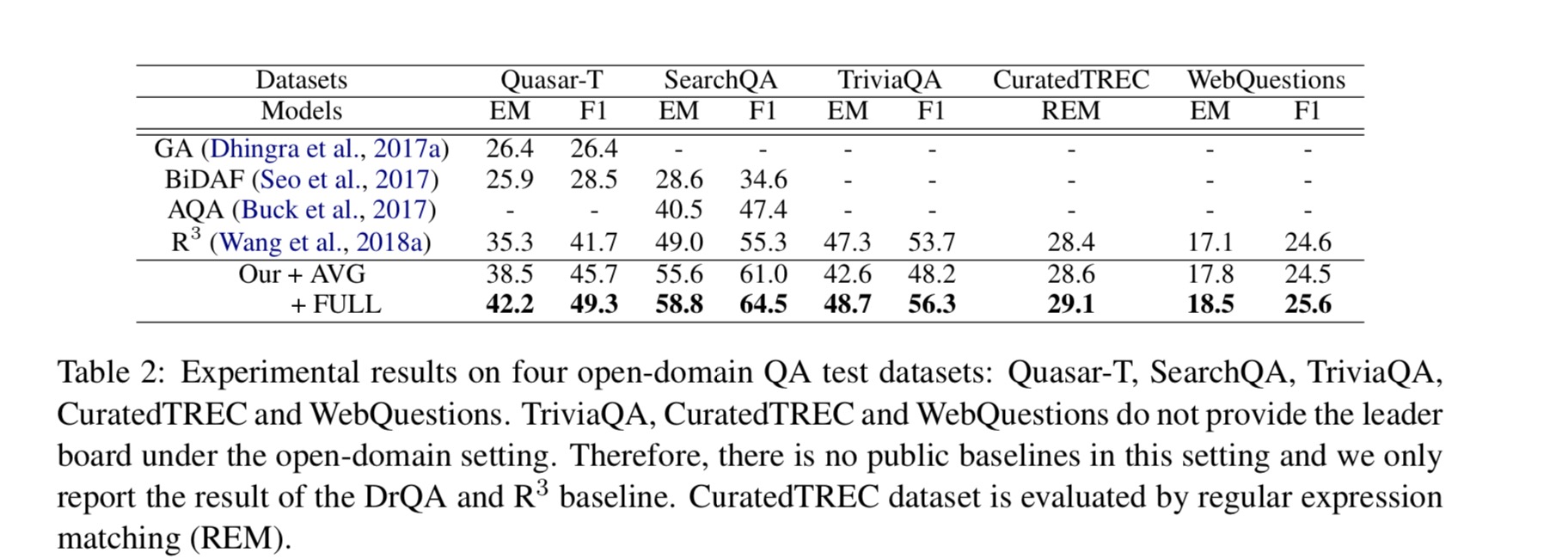
- 与其他基线相比,模型包括Our+AVG和Our+FULL在大多数数据集上都能获得更好的结果。 原因是模型可以充分利用所有检索到的段落的信息来回答问题,而其他基线模型只考虑最相关的段落。 它验证了作者的主张,即合并所有检索到的段落的丰富信息可以帮助我们更好地提取问题的答案。
- 在所有数据集上,Our+FULL模型显着且一致地优于Our+AVG模型。 它表明段落选择器可以有效地过滤掉那些无意义的已删除段落,并缓解DS-QA中错误的标签问题。
- 在TriviaQA数据集上,与R3模型相比,Our+AVG模型的性能更差。 在观察TriviaQA数据集之后,我们发现在该数据集中,只有一个或两个检索到的段落实际上包含正确的答案。 因此,简单地使用所有检索到的段落来提取答案可能会带来很多噪音。 相反,考虑到每个检索到的段落的置信度,Our+FULL模型仍然略有改进。
- 在CuratedTREC和WebQuestions数据集上,与R3模型相比,模型仅略有改进。 原因是这两个数据集的大小很小,这些DS-QA系统的性能受到与预训练数据集之间差距的严重影响。
模型缺点
为了显示使用我们的DS-QA系统的答案重新排序模型聚合提取的答案的潜在改进,我们分析到在开发集上的系统性能的极限。 通过评估前k个提取答案中的F1/EM分数,将模型与R3模型进行比较。 模型的这种top-k性能可以被视为我们模型的上限,以重新排列前k个提取的答案。
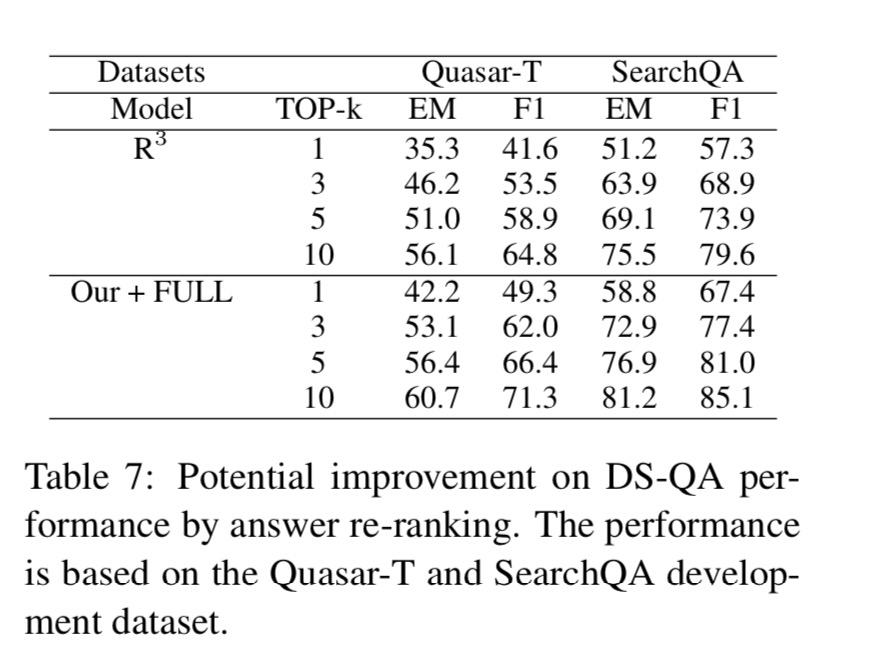
- 前3/5和前1名DS-QA表现之间存在明显差距(10-20%)。 这表明DS-QA模型远远不是最好的表现,并且仍然很有可能通过回答重新排名来改进。
- Our+FULL模型在Quasar-T和SearchQA数据集中的前1,前3和前5中的R3模型优于5%至7%。 表明汇总来自所有信息段落的信息可以有效地增强我们在DS-QA中的模型,这更有可能使用答案重新排名。
改进方向
有以下改进方向:
- 答案重新排序可以进一步改进我们的模型。 探索如何有效地重新排列提取的答案,以进一步提高性能。
- 背景知识,如事实知识,常识知识,可以有效地帮助我们进行段落选择和答案提取。 将外部知识库纳入我们的DS-QA模型,以提高其性能。
Til next time,
gentlesnow
at 15:00
